Primeros pasos con DMR
Docker Model Runner (DMR) te permite ejecutar y gestionar modelos de IA localmente utilizando Docker. Esta página te muestra cómo habilitar DMR, descargar y ejecutar un modelo, configurar los ajustes del modelo y publicar modelos personalizados.
Habilitar Docker Model Runner
Puedes habilitar DMR utilizando Docker Desktop o Docker Engine. Sigue las instrucciones a continuación según tu configuración.
Docker Desktop
- En la vista de configuración, ve a la pestaña AI.
- Selecciona la opción Enable Docker Model Runner.
- Si utilizas Windows con una GPU NVIDIA compatible, también verás y podrás seleccionar Enable GPU-backed inference.
- Opcional: para habilitar el soporte de TCP, selecciona Enable host-side TCP support.
- En el campo Port, escribe el puerto que deseas utilizar.
- Si interactúas con Model Runner desde una aplicación web local (frontend), en CORS Allows Origins, selecciona los orígenes de los cuales Model Runner debe aceptar solicitudes. Un origen es la URL donde se ejecuta tu aplicación web, por ejemplo
http://localhost:3131.
Ahora puedes utilizar el comando docker model en la CLI y ver e interactuar con tus modelos locales en la pestaña Models del panel de control (Dashboard) de Docker Desktop.
Docker Engine
Asegúrate de haber instalado Docker Engine.
Docker Model Runner está disponible como un paquete. Para instalarlo, ejecuta:
$ sudo apt-get update $ sudo apt-get install docker-model-plugin$ sudo dnf update $ sudo dnf install docker-model-pluginPrueba la instalación:
$ docker model version $ docker model run ai/smollm2
NoteEl soporte para TCP está habilitado por defecto para Docker Engine en el puerto
12434.
Actualizar DMR en Docker Engine
Para actualizar Docker Model Runner en Docker Engine, desinstálalo con
docker model uninstall-runner y luego reinstálalo:
docker model uninstall-runner --images && docker model install-runnerNoteCon el comando anterior, se conservan los modelos locales. Para eliminar los modelos durante la actualización, añade la opción
--modelsal comandouninstall-runner.
Descargar un modelo
Los modelos se guardan en la caché local.
NoteAl utilizar la CLI de Docker, también puedes descargar modelos directamente desde HuggingFace.
- Selecciona Models y ve a la pestaña Docker Hub.
- Busca el modelo que deseas y selecciona Pull.
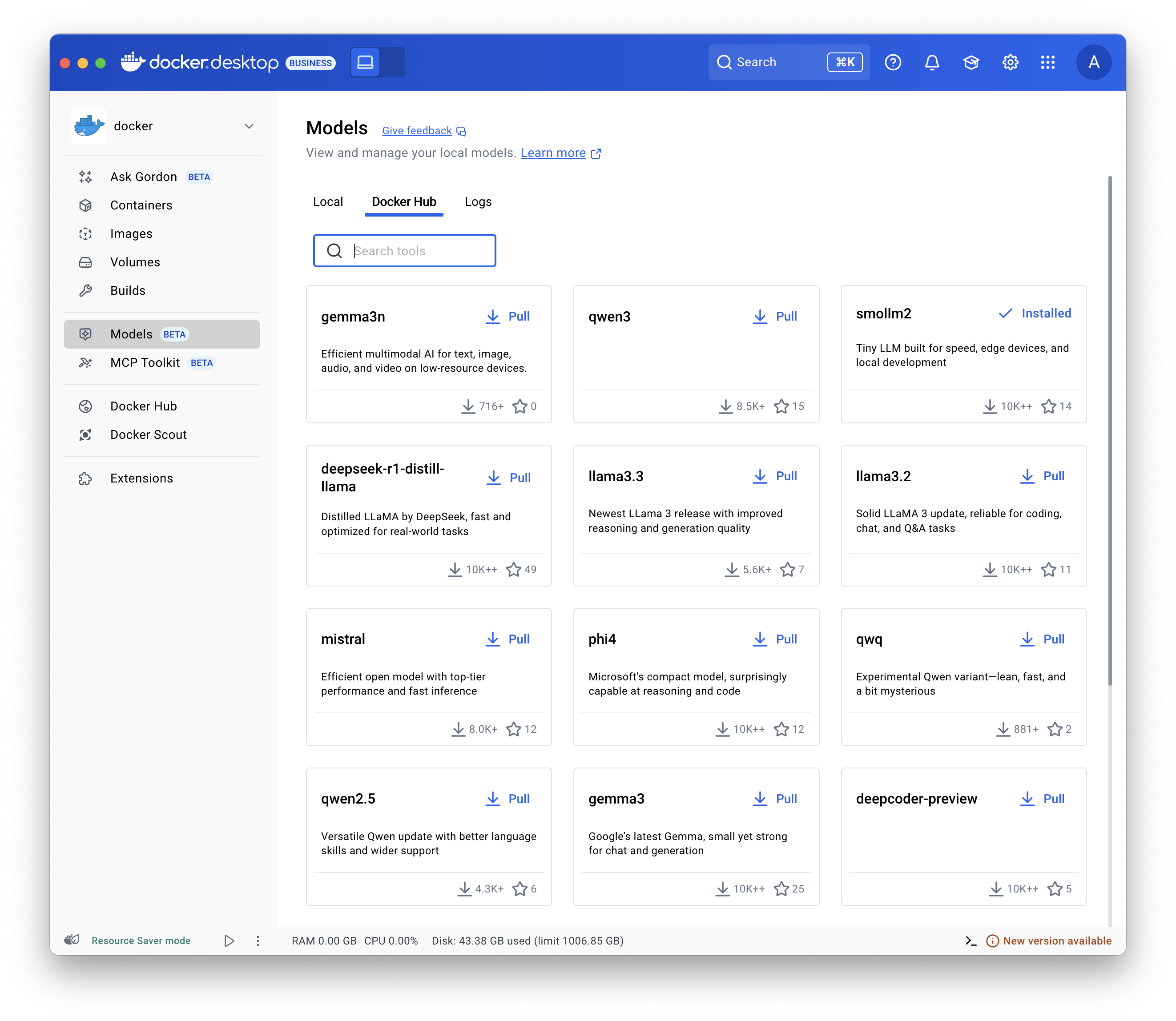
Usa el
comando docker model pull.
Por ejemplo:
docker model pull ai/smollm2:360M-Q4_K_Mdocker model pull hf.co/bartowski/Llama-3.2-1B-Instruct-GGUFEjecutar un modelo
- Selecciona Models y ve a la pestaña Local.
- Selecciona el botón de reproducción (play). Se abrirá la pantalla de chat interactivo.
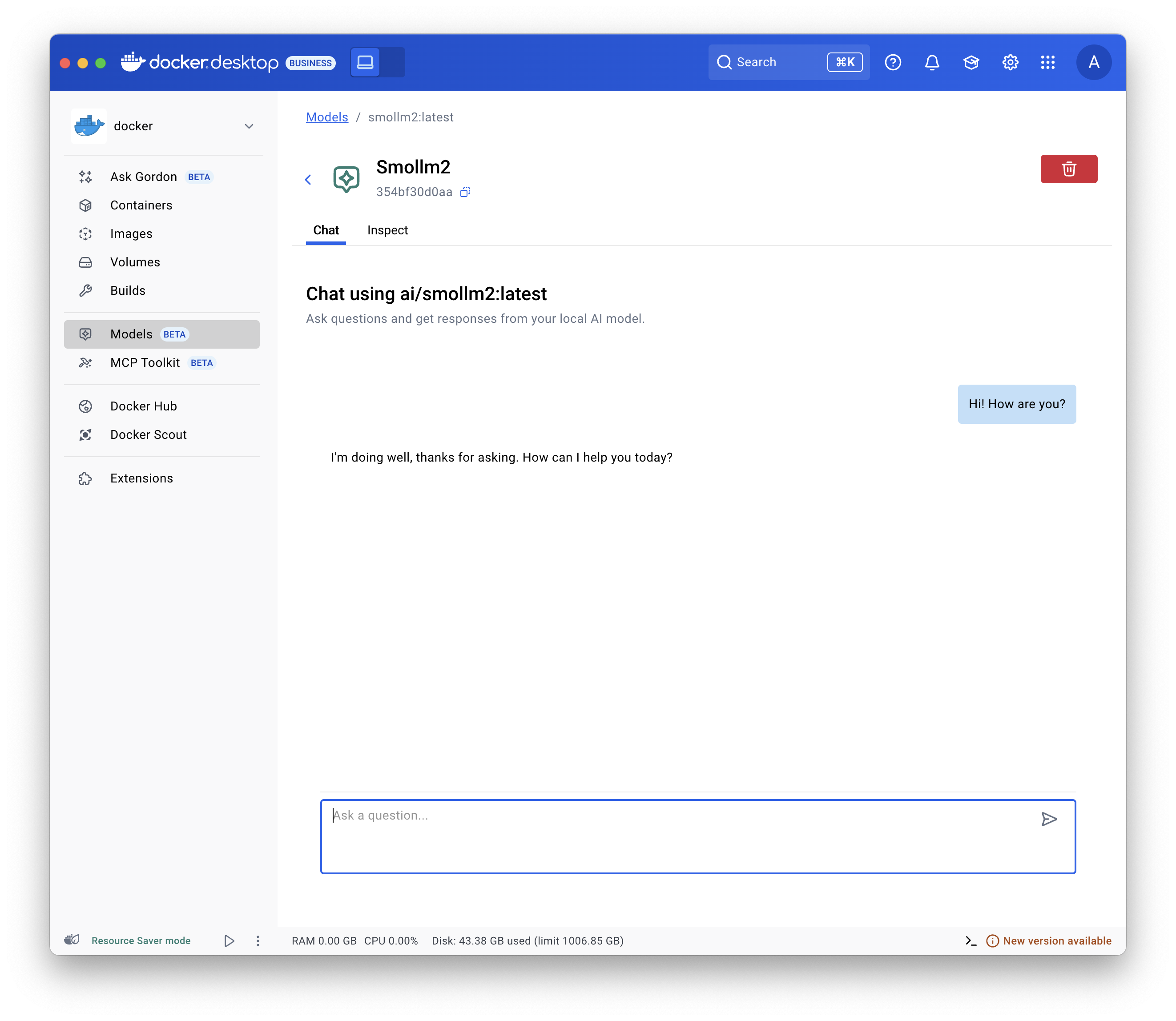
Usa el
comando docker model run.
Configurar un modelo
Puedes configurar un modelo, como su límite máximo de tokens y más, utilizando Docker Compose. Consulta Modelos y Compose - Opciones de configuración de modelos.
Publicar un modelo
NoteEsto funciona para cualquier registro de contenedores compatible con artefactos de OCI, no solo para Docker Hub.
Puedes etiquetar modelos existentes con un nuevo nombre y publicarlos bajo un espacio de nombres y repositorio diferentes:
# Etiquetar un modelo descargado con un nuevo nombre
$ docker model tag ai/smollm2 myorg/smollm2
# Subirlo a Docker Hub
$ docker model push myorg/smollm2Para obtener más detalles, consulta la documentación de los comandos
docker model tag y
docker model push.
También puedes empaquetar un archivo de modelo en formato GGUF como un artefacto de OCI y publicarlo en Docker Hub.
# Descargar un archivo de modelo en formato GGUF, por ejemplo desde HuggingFace
$ curl -L -o model.gguf https://huggingface.co/TheBloke/Mistral-7B-v0.1-GGUF/resolve/main/mistral-7b-v0.1.Q4_K_M.gguf
# Empaquetarlo como artefacto de OCI y subirlo a Docker Hub
$ docker model package --gguf "$(pwd)/model.gguf" --push myorg/mistral-7b-v0.1:Q4_K_MPara obtener más detalles, consulta la documentación del comando
docker model package.
Resolución de problemas
Mostrar los registros (logs)
Para solucionar problemas, muestra los registros:
Selecciona Models y ve a la pestaña Logs.
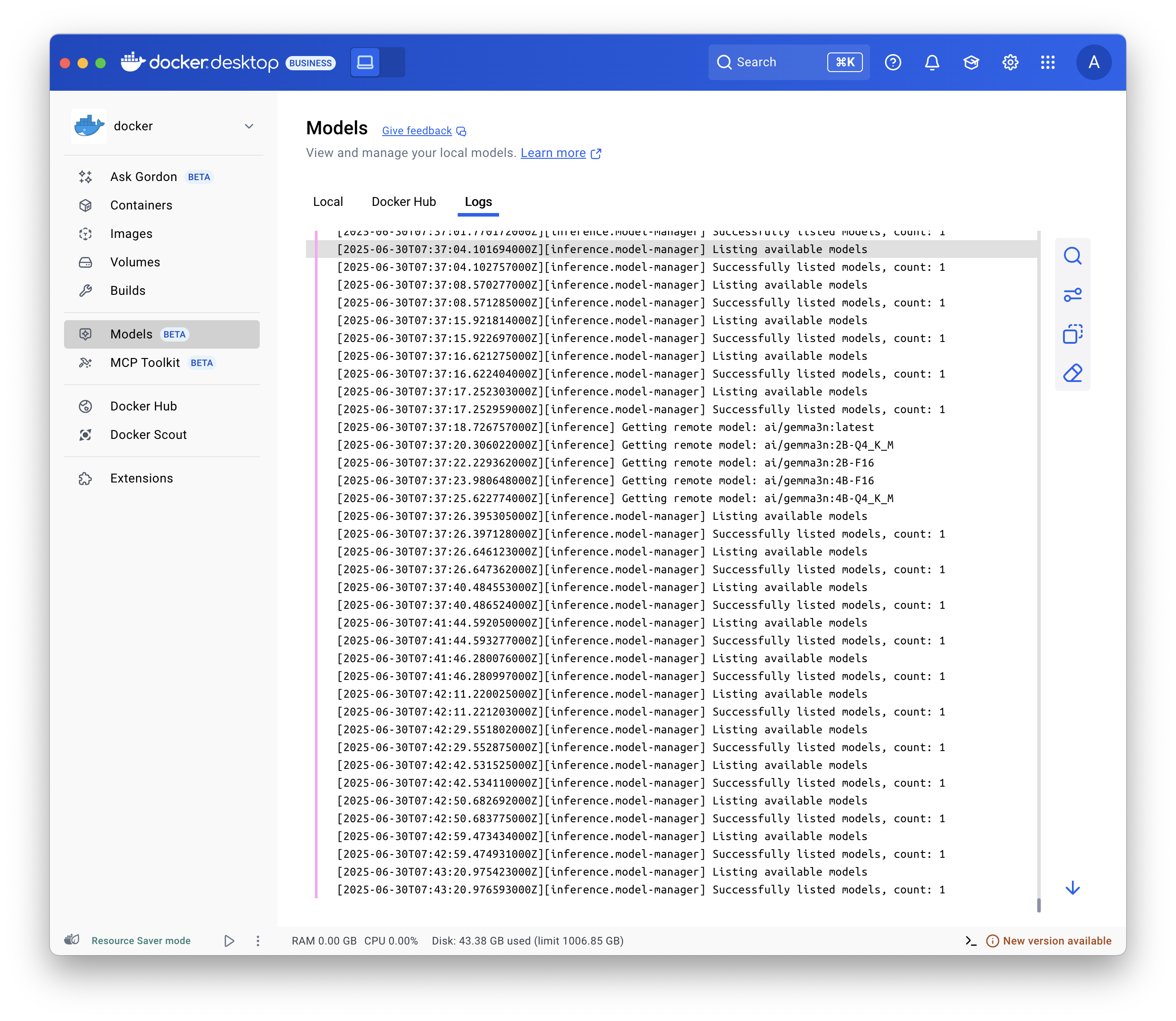
Usa el
comando docker model logs.
Inspeccionar solicitudes y respuestas
Inspeccionar las solicitudes y respuestas te ayuda a diagnosticar problemas relacionados con los modelos. Por ejemplo, puedes evaluar el uso del contexto para verificar que te mantienes dentro de la ventana de contexto del modelo, o mostrar el cuerpo completo de una solicitud para controlar los parámetros que estás pasando a tus modelos al desarrollar con un framework.
En Docker Desktop, para inspeccionar las solicitudes y respuestas de cada modelo:
- Selecciona Models y ve a la pestaña Requests. Esta vista muestra todas las solicitudes a todos los modelos:
- La hora en que se envió la solicitud.
- El nombre y la versión del modelo.
- El prompt/solicitud.
- El uso del contexto.
- El tiempo que tardó en generarse la respuesta.
- Selecciona una de las solicitudes para mostrar más detalles:
- En la pestaña Overview, puedes ver el uso de tokens, los metadatos de la respuesta, la velocidad de generación y el prompt y respuesta reales.
- En las pestañas Request y Response, puedes ver el payload JSON completo de la solicitud y de la respuesta.
NoteTambién puedes mostrar las solicitudes de un modelo específico seleccionando un modelo y luego ve a la pestaña Requests.
Páginas relacionadas
- Referencia de la API - Documentación de la API compatible con OpenAI y Ollama
- Opciones de configuración - Tamaño del contexto y parámetros de tiempo de ejecución
- Motores de inferencia - Detalles de llama.cpp y vLLM
- Integraciones de IDE - Conecta Cline, Continue, Cursor y más
- Integración de Open WebUI - Configura una interfaz de chat web
- Modelos y Compose - Usa modelos en aplicaciones de Compose
- Referencia de la CLI de Docker Model Runner - Documentación completa de la CLI