Cómo funcionan los servicios
Para implementar una imagen de aplicación cuando Docker Engine está en modo Swarm, creas un servicio. Con frecuencia, un servicio es la imagen de un microservicio dentro del contexto de una aplicación más grande. Ejemplos de servicios podrían incluir un servidor HTTP, una base de datos o cualquier otro tipo de programa ejecutable que desees ejecutar en un entorno distribuido.
Al crear un servicio, especificas qué imagen de contenedor usar y qué comandos ejecutar dentro de los contenedores en ejecución. También defines opciones para el servicio que incluyen:
- El puerto donde el swarm pone a disposición el servicio fuera del swarm.
- Una red superpuesta (overlay network) para que el servicio se conecte a otros servicios del swarm.
- Reservas y límites de CPU y memoria.
- Una política de actualización continua (rolling update policy).
- El número de réplicas de la imagen a ejecutar en el swarm.
Servicios, tareas y contenedores
Cuando implementas el servicio en el swarm, el administrador del swarm acepta tu definición de servicio como el estado deseado para el mismo. Luego, programa el servicio en nodos del swarm como una o más tareas de réplica. Las tareas se ejecutan de forma independiente unas de otras en los nodos del swarm.
Por ejemplo, imagina que deseas equilibrar la carga entre tres instancias de un oyente HTTP (HTTP listener). El siguiente diagrama muestra un servicio de oyente HTTP con tres réplicas. Cada una de las tres instancias del oyente es una tarea en el swarm.
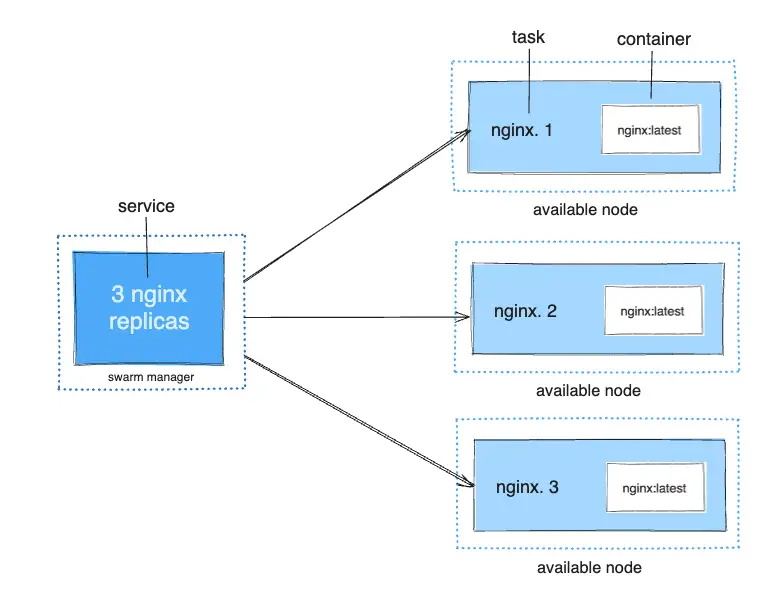
Un contenedor es un proceso aislado. En el modelo del modo Swarm, cada tarea invoca exactamente un contenedor. Una tarea es análoga a un "slot" (ranura) donde el programador coloca un contenedor. Una vez que el contenedor está activo, el programador reconoce que la tarea está en estado de ejecución. Si el contenedor falla las pruebas de estado (health checks) o finaliza, la tarea finaliza.
Tareas y programación
Una tarea es la unidad atómica de programación dentro de un swarm. Cuando declaras un estado de servicio deseado creando o actualizando un servicio, el orquestador realiza el estado deseado programando tareas. Por ejemplo, defines un servicio que le indica al orquestador que mantenga tres instancias de un oyente HTTP en ejecución en todo momento. El orquestador responde creando tres tareas. Cada tarea es un slot que el programador llena generando un contenedor. El contenedor es la instanciación de la tarea. Si posteriormente una tarea del oyente HTTP falla su prueba de estado o se cae (crashes), el orquestador crea una nueva tarea de réplica que genera un contenedor nuevo.
Una tarea es un mecanismo unidireccional. Progresa de manera monótona a través de una serie de estados: ASSIGNED, PREPARING, RUNNING, etc. Si la tarea falla, el orquestador elimina la tarea y su contenedor, y luego crea una nueva tarea para reemplazarla según el estado deseado especificado por el servicio.
La lógica subyacente del modo Swarm de Docker es un programador y orquestador de propósito general. Las abstracciones de servicio y tarea en sí mismas no conocen los contenedores que implementan. Hipotéticamente, se podrían implementar otros tipos de tareas, como tareas de máquina virtual o tareas de procesos no contenedorizados. El programador y el orquestador son agnósticos respecto al tipo de tarea. Sin embargo, Docker solo admite tareas de contenedor.
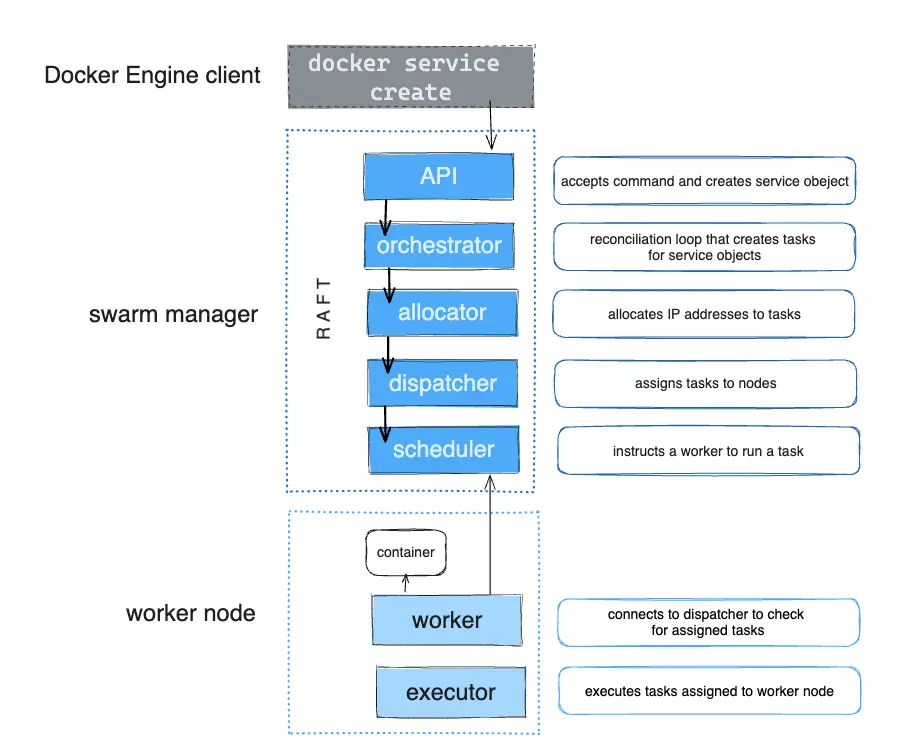
El siguiente diagrama muestra cómo el modo Swarm acepta solicitudes de creación de servicios y programa tareas en los nodos trabajadores.
Servicios pendientes
Un servicio puede estar configurado de tal manera que ningún nodo actualmente en el swarm pueda ejecutar sus tareas. En este caso, el servicio permanece en estado pending (pendiente). Aquí hay algunos ejemplos de cuándo un servicio podría permanecer en estado pending.
TipSi tu única intención es evitar que un servicio se implemente, escala el servicio a 0 en su lugar, en vez de intentar configurarlo de tal manera que permanezca en
pending.
Si todos los nodos están en pausa o drenados (drained) y creas un servicio, este quedará pendiente hasta que un nodo esté disponible. En realidad, el primer nodo que esté disponible recibirá todas las tareas, por lo que esto no es una buena práctica en un entorno de producción.
Puedes reservar una cantidad específica de memoria para un servicio. Si ningún nodo en el swarm tiene la cantidad de memoria requerida, el servicio permanece en estado pendiente hasta que esté disponible un nodo que pueda ejecutar sus tareas. Si especificas un valor muy grande, como 500 GB, la tarea permanecerá pendiente para siempre, a menos que realmente dispongas de un nodo que pueda satisfacerla.
Puedes imponer restricciones de ubicación (placement constraints) en el servicio, y es posible que estas restricciones no se puedan cumplir en un momento dado.
Este comportamiento ilustra que los requisitos y la configuración de tus tareas no están estrechamente vinculados al estado actual del swarm. Como administrador de un swarm, declaras el estado deseado de tu swarm y el administrador trabaja con los nodos del swarm para crear ese estado. No necesitas microgestionar las tareas en el swarm.
Servicios replicados y globales
Hay dos tipos de implementaciones de servicios: replicadas y globales.
Para un servicio replicado, especificas la cantidad de tareas idénticas que deseas ejecutar. Por ejemplo, decides implementar un servicio HTTP con tres réplicas, cada una sirviendo el mismo contenido.
Un servicio global es un servicio que ejecuta una tarea en cada nodo. No hay un número predeterminado de tareas. Cada vez que agregas un nodo al swarm, el orquestador crea una tarea y el programador la asigna al nuevo nodo. Buenos candidatos para servicios globales son los agentes de monitoreo, los escáneres antivirus u otros tipos de contenedores que desees ejecutar en cada nodo del swarm.
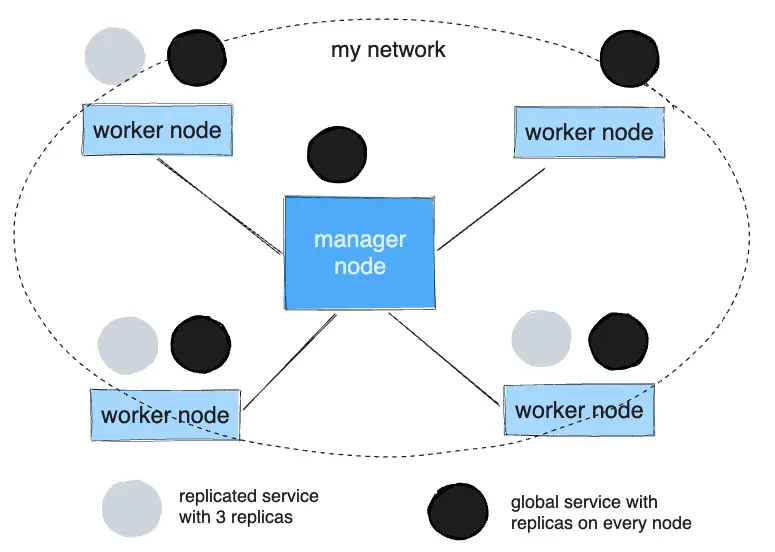
El siguiente diagrama muestra una réplica de tres servicios en gris y un servicio global en negro.