Desplegar servicios en un swarm
Los servicios de Swarm utilizan un modelo declarativo, lo que significa que defines el estado deseado del servicio y confías en Docker para mantener este estado. El estado incluye información como (entre otros):
- El nombre y la etiqueta de la imagen que deben ejecutar los contenedores del servicio.
- Cuántos contenedores participan en el servicio.
- Si se exponen puertos a clientes fuera del swarm.
- Si el servicio debe iniciarse automáticamente cuando se inicia Docker.
- El comportamiento específico que ocurre cuando el servicio se reinicia (como si se utiliza un reinicio continuo o rolling restart).
- Características de los nodos donde se puede ejecutar el servicio (como restricciones de recursos y preferencias de ubicación).
Para obtener una descripción general del modo Swarm, consulta los Conceptos clave del modo Swarm. Para una descripción de cómo funcionan los servicios, consulta Cómo funcionan los servicios.
Crear un servicio
Para crear un servicio de una sola réplica sin configuración adicional, solo necesitas proporcionar el nombre de la imagen. Este comando inicia un servicio Nginx con un nombre generado aleatoriamente y sin puertos publicados. Este es un ejemplo básico, ya que no puedes interactuar con el servicio Nginx.
$ docker service create nginx
El servicio se planifica en un nodo disponible. Para confirmar que el servicio se creó e inició correctamente, utiliza el comando docker service ls:
$ docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
a3iixnklxuem quizzical_lamarr replicated 1/1 docker.io/library/nginx@sha256:41ad9967ea448d7c2b203c699b429abe1ed5af331cd92533900c6d77490e0268
Los servicios creados no siempre se ejecutan de inmediato. Un servicio puede estar en estado pendiente (pending) si su imagen no está disponible, si ningún nodo cumple con los requisitos configurados para el servicio, o por otras razones. Consulta Servicios pendientes para obtener más información.
Para proporcionar un nombre para tu servicio, utiliza la opción --name:
$ docker service create --name my_web nginx
Al igual que con los contenedores independientes, puedes especificar un comando que deben ejecutar los contenedores del servicio, añadiéndolo después del nombre de la imagen. Este ejemplo inicia un servicio llamado helloworld que utiliza una imagen alpine y ejecuta el comando ping docker.com:
$ docker service create --name helloworld alpine ping docker.com
También puedes especificar una etiqueta de imagen para que la use el servicio. Este ejemplo modifica el anterior para utilizar la etiqueta alpine:3.6:
$ docker service create --name helloworld alpine:3.6 ping docker.com
Para más detalles sobre la resolución de etiquetas de imagen, consulta Especificar la versión de la imagen que debe utilizar el servicio.
gMSA para Swarm
NoteEste ejemplo solo funciona para un contenedor de Windows.
Swarm permite utilizar una configuración de Docker como una especificación de credenciales de gMSA, un requisito para las aplicaciones autenticadas con Active Directory. Esto reduce la carga de trabajo de distribuir especificaciones de credenciales a los nodos en los que se utilizan.
El siguiente ejemplo asume que ya existen una gMSA y su especificación de credenciales (llamada credspec.json), y que los nodos en los que se realiza el despliegue están configurados correctamente para la gMSA.
Para utilizar una configuración como especificación de credenciales, primero crea la configuración de Docker que contiene la especificación de credenciales:
$ docker config create credspec credspec.json
Ahora deberías tener una configuración de Docker llamada credspec y puedes crear un servicio utilizando esta especificación de credenciales. Para hacerlo, utiliza la opción --credential-spec con el nombre de la configuración, así:
$ docker service create --credential-spec="config://credspec" <your image>
Tu servicio utiliza la especificación de credenciales de gMSA cuando se inicia, pero a diferencia de una configuración de Docker típica (que se utiliza pasando la opción --config), la especificación de credenciales no se monta en el contenedor.
Crear un servicio utilizando una imagen en un registro privado
Si tu imagen está disponible en un registro privado que requiere inicio de sesión, utiliza la opción --with-registry-auth con docker service create, después de haber iniciado sesión. Si tu imagen está almacenada en registry.example.com, que es un registro privado, utiliza un comando como el siguiente:
$ docker login registry.example.com
$ docker service create \
--with-registry-auth \
--name my_service \
registry.example.com/acme/my_image:latest
Esto pasa el token de inicio de sesión de tu cliente local a los nodos del swarm donde se despliega el servicio, utilizando los registros WAL cifrados. Con esta información, los nodos pueden iniciar sesión en el registro y descargar (pull) la imagen.
Proporcionar especificaciones de credenciales para cuentas de servicio administradas
En la Enterprise Edition 3.0, la seguridad se mejora mediante la distribución y gestión centralizada de credenciales de Cuenta de Servicio Administrada de Grupo (gMSA) utilizando la funcionalidad de configuración de Docker. Swarm permite utilizar una configuración de Docker como especificación de credenciales de gMSA, lo que reduce la carga de distribuir especificaciones de credenciales a los nodos en los que se utilizan.
NoteEsta opción solo es aplicable a servicios que utilizan contenedores de Windows.
Los archivos de especificación de credenciales se aplican en tiempo de ejecución, eliminando la necesidad de archivos de especificación de credenciales basados en el host o entradas de registro; no se escriben credenciales de gMSA en el disco de los nodos trabajadores. Puedes poner las especificaciones de credenciales a disposición de los nodos trabajadores que ejecutan swarm kit antes de que comience un contenedor. Al desplegar un servicio utilizando una configuración basada en gMSA, la especificación de credenciales se pasa directamente al motor de ejecución de los contenedores en ese servicio.
La opción --credential-spec debe tener uno de los siguientes formatos:
file://<nombre-archivo>: El archivo de referencia debe estar presente en el subdirectorioCredentialSpecsdentro del directorio de datos de Docker, que por defecto esC:\ProgramData\Docker\en Windows. Por ejemplo, al especificarfile://spec.jsonse cargaC:\ProgramData\Docker\CredentialSpecs\spec.json.registry://<nombre-valor>: La especificación de credenciales se lee del registro de Windows en el host del demonio.config://<nombre-config>: El nombre de la configuración se convierte automáticamente al ID de configuración en la CLI. Se utiliza la especificación de credenciales contenida en laconfigespecificada.
El siguiente ejemplo simple recupera el nombre de gMSA y el contenido JSON de tu instancia de Active Directory (AD):
$ name="mygmsa"
$ contents="{...}"
$ echo $contents > contents.json
Asegúrate de que los nodos en los que realizas el despliegue estén configurados correctamente para la gMSA.
To utilizar una configuración como especificación de credenciales, crea una configuración de Docker a partir de un archivo de especificación de credenciales llamado credspec.json. Puedes especificar cualquier nombre para identificar la configuración.
$ docker config create --label com.docker.gmsa.name=mygmsa credspec credspec.json
Ahora puedes crear un servicio utilizando esta especificación de credenciales. Especifica la opción --credential-spec junto con el nombre de la configuración:
$ docker service create --credential-spec="config://credspec" <your image>
Tu servicio utiliza la especificación de credenciales de gMSA al iniciarse, pero a diferencia de una configuración de Docker típica (que se utiliza pasando la opción --config), la especificación de credenciales no se monta en el contenedor.
Update a service
Puedes cambiar casi todo sobre un servicio existente utilizando el comando docker service update. Al actualizar un servicio, Docker detiene sus contenedores y los reinicia con la nueva configuración.
Dado que Nginx es un servicio web, funciona mucho mejor si publicas el puerto 80 para los clientes fuera del swarm. Puedes especificar esto al crear el servicio utilizando la opción -p o --publish. Al actualizar un servicio existente, la opción es --publish-add. También existe una opción --publish-rm para eliminar un puerto que fue publicado previamente.
Asumiendo que el servicio my_web de la sección anterior todavía existe, utiliza el siguiente comando para actualizarlo y publicar el puerto 80.
$ docker service update --publish-add 80 my_web
Para verificar que funcionó, utiliza docker service ls:
$ docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
4nhxl7oxw5vz my_web replicated 1/1 docker.io/library/nginx@sha256:41ad9967ea448d7c2b203c699b429abe1ed5af331cd92533900c6d77490e0268 *:0->80/tcp
Para obtener más información sobre cómo funciona la publicación de puertos, consulta publicar puertos.
Puedes actualizar casi cualquier detalle de configuración sobre un servicio existente, incluyendo el nombre de la imagen y la etiqueta que ejecuta. Consulta Actualizar la imagen de un servicio después de su creación.
Eliminar un servicio
Para eliminar un servicio, utiliza el comando docker service remove. Puedes eliminar un servicio por su ID o por su nombre, como se muestra en la salida del comando docker service ls. El siguiente comando elimina el servicio my_web.
$ docker service remove my_web
Detalles de configuración del servicio
Las siguientes secciones proporcionan detalles sobre la configuración del servicio. Este tema no cubre cada opción o escenario. En casi todos los casos donde puedes definir una configuración al crear el servicio, también puedes actualizar la configuración de un servicio existente de manera similar.
Consulta las referencias de la línea de comandos para
docker service create y
docker service update, o ejecuta uno de esos comandos con la opción --help.
Configurar el entorno de ejecución
Puedes configurar las siguientes opciones para el entorno de ejecución en el contenedor:
- Variables de entorno utilizando la opción
--env - El directorio de trabajo dentro del contenedor utilizando la opción
--workdir - El nombre de usuario o UID utilizando la opción
--user
Los contenedores del siguiente servicio tienen una variable de entorno $MYVAR establecida en myvalue, se ejecutan desde el directorio /tmp/ y se ejecutan como el usuario my_user.
$ docker service create --name helloworld \
--env MYVAR=myvalue \
--workdir /tmp \
--user my_user \
alpine ping docker.com
Actualizar el comando que ejecuta un servicio existente
Para actualizar el comando que ejecuta un servicio existente, puedes utilizar la opción --args. El siguiente ejemplo actualiza un servicio existente llamado helloworld para que ejecute el comando ping docker.com en lugar de cualquier comando que estuviera ejecutando antes:
$ docker service update --args "ping docker.com" helloworld
Especificar la versión de la imagen que debe utilizar el servicio
Al crear un servicio sin especificar detalles sobre la versión de la imagen que se va a utilizar, el servicio utiliza la versión etiquetada con latest. Puedes forzar al servicio a utilizar una versión específica de la imagen de varias formas diferentes, según el resultado que desees.
La versión de una imagen se puede expresar de varias formas diferentes:
Si especificas una etiqueta, el administrador (o el cliente Docker, si utilizas confianza de contenido (content trust)) resuelve esa etiqueta a un resumen (digest). Cuando se recibe la solicitud para crear una tarea de contenedor en un nodo trabajador, el nodo trabajador solo ve el resumen, no la etiqueta.
$ docker service create --name="myservice" ubuntu:16.04Algunas etiquetas representan lanzamientos específicos, como
ubuntu:16.04. Las etiquetas de este tipo casi siempre se resuelven a un resumen estable con el tiempo. Se recomienda que utilices este tipo de etiqueta cuando sea posible.Otros tipos de etiquetas, como
latestonightly, pueden resolverse a un nuevo resumen a menudo, según la frecuencia con la que el autor de la imagen actualice la etiqueta. No se recomienda ejecutar servicios utilizando una etiqueta que se actualice frecuentemente, para evitar que diferentes tareas de réplica del servicio utilicen distintas versiones de la imagen.Si no especificas ninguna versión, por convención la etiqueta
latestde la imagen se resuelve a un resumen. Los nodos trabajadores utilizan la imagen en este resumen al crear la tarea del servicio.Por lo tanto, los siguientes dos comandos son equivalentes:
$ docker service create --name="myservice" ubuntu $ docker service create --name="myservice" ubuntu:latestSi especificas un resumen directamente, siempre se utilizará esa versión exacta de la imagen al crear las tareas del servicio.
$ docker service create \ --name="myservice" \ ubuntu:16.04@sha256:35bc48a1ca97c3971611dc4662d08d131869daa692acb281c7e9e052924e38b1
Al crear un servicio, la etiqueta de la imagen se resuelve en el resumen específico al que apunta la etiqueta en el momento de la creación del servicio. Los nodos trabajadores para ese servicio utilizarán ese resumen específico indefinidamente a menos que el servicio se actualice explícitamente. Esta característica es especialmente importante si utilizas etiquetas que cambian a menudo como latest, porque garantiza que todas las tareas del servicio utilicen la misma versión de la imagen.
NoteSi la confianza de contenido (content trust) está habilitada, el cliente resuelve la etiqueta de la imagen a un resumen antes de comunicarse con el administrador del swarm, para verificar que la imagen esté firmada. Por lo tanto, si utilizas la confianza de contenido, el administrador del swarm recibe la solicitud ya resuelta. En este caso, si el cliente no puede resolver la imagen a un resumen, la solicitud fallará.
Si el administrador no puede resolver la etiqueta a un resumen, cada nodo trabajador es responsable de resolver la etiqueta a un resumen, y diferentes nodos pueden utilizar distintas versiones de la imagen. Si esto sucede, se registra una advertencia como la siguiente, sustituyendo los marcadores de posición por información real.
unable to pin image <IMAGE-NAME> to digest: <REASON>Para ver el resumen actual de una imagen, ejecuta el comando docker inspect <IMAGE>:<TAG> y busca la línea RepoDigests. El siguiente es el resumen actual para ubuntu:latest al momento de escribir este contenido. La salida está truncada para mayor claridad.
$ docker inspect ubuntu:latest
"RepoDigests": [
"ubuntu@sha256:35bc48a1ca97c3971611dc4662d08d131869daa692acb281c7e9e052924e38b1"
],Después de crear un servicio, su imagen nunca se actualiza a menos que ejecutes explícitamente docker service update con la opción --image como se describe a continuación. Otras operaciones de actualización, como la escala del servicio, adición o eliminación de redes o volúmenes, renombrado del servicio o cualquier otro tipo de operación de actualización, no actualizan la imagen del servicio.
Actualizar la imagen de un servicio después de su creación
Cada etiqueta representa un resumen, similar a un hash de Git. Algunas etiquetas, como latest, se actualizan a menudo para apuntar a un nuevo resumen. Otras, como ubuntu:16.04, representan una versión de software lanzada y no se espera que se actualicen para apuntar a un nuevo resumen a menudo, si es que lo hacen. Al crear un servicio, este se limita a crear tareas utilizando un resumen específico de una imagen hasta que actualices el servicio utilizando service update con la opción --image.
Cuando ejecutas service update con la opción --image, el administrador del swarm consulta Docker Hub o tu registro privado de Docker para obtener el resumen al que apunta actualmente la etiqueta y actualiza las tareas del servicio para utilizar ese resumen.
NoteSi utilizas la confianza de contenido (content trust), el cliente de Docker resuelve la imagen y el administrador del swarm recibe la imagen y el resumen, en lugar de una etiqueta.
Normalmente, el administrador puede resolver la etiqueta a un nuevo resumen y el servicio se actualiza, volviendo a desplegar cada tarea para utilizar la nueva imagen. Si el administrador no puede resolver la etiqueta o se produce algún otro problema, las siguientes dos secciones describen qué esperar.
Si el administrador resuelve la etiqueta
Si el administrador del swarm puede resolver la etiqueta de la imagen a un resumen, indica a los nodos trabajadores que vuelvan a desplegar las tareas y utilicen la imagen en ese resumen.
- Si un nodo trabajador tiene la imagen en caché con ese resumen, la utiliza.
- Si no, intenta descargar (pull) la imagen desde Docker Hub o el registro privado.
- Si tiene éxito, la tarea se despliega utilizando la nueva imagen.
- Si el nodo trabajador no puede descargar la imagen, el despliegue del servicio fallará en ese nodo trabajador. Docker intentará de nuevo desplegar la tarea, posiblemente en un nodo trabajador diferente.
Si el administrador no puede resolver la etiqueta
Si el administrador del swarm no puede resolver la imagen a un resumen, no todo está perdido:
- El administrador indica a los nodos trabajadores que vuelvan a desplegar las tareas utilizando la imagen con esa etiqueta.
- Si el nodo trabajador tiene una imagen en caché local que se resuelve con esa etiqueta, utiliza esa imagen.
- Si el nodo trabajador no tiene una imagen en caché local que se resuelva con la etiqueta, intenta conectarse a Docker Hub o al registro privado para descargar la imagen con esa etiqueta.
- Si tiene éxito, el nodo trabajador utiliza esa imagen.
- Si falla, la tarea no se desplegará y el administrador intentará de nuevo desplegar la tarea, posiblemente en un nodo trabajador diferente.
Publicar puertos
Al crear un servicio de swarm, puedes publicar los puertos de ese servicio para hosts fuera del swarm de dos formas:
- Puedes confiar en la malla de enrutamiento. Al publicar un puerto de servicio, el swarm hace que el servicio sea accesible en el puerto de destino en cada nodo, independientemente de si hay una tarea para el servicio ejecutándose en ese nodo o no. Esto es menos complejo y es la opción correcta para muchos tipos de servicios.
- Puedes publicar el puerto de una tarea de servicio directamente en el nodo del swarm donde se está ejecutando ese servicio. Esto omite la malla de enrutamiento y proporciona la máxima flexibilidad, incluida la capacidad para desarrollar tu propio marco de enrutamiento. Sin embargo, eres responsable de realizar el seguimiento de dónde se está ejecutando cada tarea, redirigir las solicitudes a las tareas y balancear la carga entre los nodos.
Keep leyendo para obtener más información y casos de uso para cada uno de estos métodos.
Publicar puertos de un servicio utilizando la malla de enrutamiento
Para publicar los puertos de un servicio de forma externa al swarm, utiliza la opción --publish <PUBLISHED-PORT>:<SERVICE-PORT>. El swarm hace que el servicio sea accesible en el puerto publicado en cada nodo del swarm. Si un host externo se conecta a ese puerto en cualquier nodo del swarm, la malla de enrutamiento lo redirige a una tarea. El host externo no necesita conocer las direcciones IP ni los puertos utilizados internamente por las tareas del servicio para interactuar con él. Cuando un usuario o proceso se conecta a un servicio, cualquier nodo trabajador que ejecute una tarea del servicio puede responder. Para obtener más detalles sobre las redes de servicios de swarm, consulta Gestionar las redes de servicios de Swarm.
Ejemplo: Ejecutar un servicio Nginx de tres tareas en un swarm de 10 nodos
Imagina que tienes un swarm de 10 nodos y despliegas un servicio Nginx que ejecuta tres tareas:
$ docker service create --name my_web \
--replicas 3 \
--publish published=8080,target=80 \
nginx
Tres tareas se ejecutan en hasta tres nodos. No necesitas saber qué nodos están ejecutando las tareas; conectarte al puerto 8080 en cualquiera de los 10 nodos te conecta a una de las tres tareas de nginx. Puedes probar esto utilizando curl. El siguiente ejemplo asume que localhost es uno de los nodos del swarm. Si este no es el caso, o si localhost no se resuelve a una dirección IP en tu host, sustitúyela por la dirección IP del host o el nombre de host resoluble.
La salida HTML está truncada:
$ curl localhost:8080
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...truncated...
</html>
Las conexiones subsiguientes se pueden redirigir al mismo nodo del swarm o a uno diferente.
Publicar puertos de un servicio directamente en el nodo del swarm
El uso de la malla de enrutamiento puede no ser la opción correcta para tu aplicación si necesitas tomar decisiones de enrutamiento basadas en el estado de la aplicación o si necesitas un control total del proceso para redirigir las solicitudes a las tareas de tu servicio. Para publicar el puerto de un servicio directamente en el nodo donde se está ejecutando, utiliza la opción mode=host en la opción --publish.
NoteSi publicas los puertos de un servicio directamente en el nodo del swarm utilizando
mode=hosty también establecespublished=<PORT>, esto crea una limitación implícita de que solo puedes ejecutar una tarea para ese servicio en un nodo de swarm determinado. Puedes solucionar esto especificandopublishedsin definir un puerto, lo que hace que Docker asigne un puerto aleatorio para cada tarea.Además, si utilizas
mode=hosty no utilizas la opción--mode=globalal ejecutardocker service create, es difícil saber qué nodos están ejecutando el servicio para redirigirles el trabajo.
Ejemplo: Ejecutar un servicio de servidor web nginx en cada nodo del swarm
nginx es un proxy inverso, balanceador de carga, caché HTTP y servidor web de código abierto. Si ejecutas nginx como un servicio utilizando la malla de enrutamiento, conectarte al puerto de nginx en cualquier nodo del swarm te mostrará la página web de (efectivamente) un nodo aleatorio del swarm que ejecuta el servicio.
El siguiente ejemplo ejecuta nginx como un servicio en cada nodo de tu swarm y expone el puerto de nginx localmente en cada nodo.
$ docker service create \
--mode global \
--publish mode=host,target=80,published=8080 \
--name=nginx \
nginx:latest
Puedes acceder al servidor nginx en el puerto 8080 de cada nodo del swarm. Si añades un nodo al swarm, se iniciará una tarea de nginx en él. No puedes iniciar otro servicio o contenedor en ningún nodo del swarm que se vincule al puerto 8080.
NoteEste es un ejemplo puramente ilustrativo. La creación de un marco de enrutamiento de capa de aplicación para un servicio de múltiples niveles es compleja y está fuera del alcance de este tema.
Conectar el servicio a una red superpuesta
Puedes utilizar redes superpuestas para conectar uno o más servicios dentro del swarm.
Primero, crea la red superpuesta en un nodo administrador utilizando el comando docker network create con la opción --driver overlay.
$ docker network create --driver overlay my-network
Después de crear una red superpuesta en modo swarm, todos los nodos administradores tienen acceso a ella.
Puedes crear un nuevo servicio y pasar la opción --network para conectar el servicio a la red superpuesta:
$ docker service create \
--replicas 3 \
--network my-network \
--name my-web \
nginx
El swarm extiende my-network a cada nodo que ejecuta el servicio.
También puedes conectar un servicio existente a una red superpuesta utilizando la opción --network-add.
$ docker service update --network-add my-network my-web
Para desconectar un servicio en ejecución de una red, utiliza la opción --network-rm.
$ docker service update --network-rm my-network my-web
Para obtener más información sobre las redes superpuestas y el descubrimiento de servicios, consulta Conectar servicios a una red superpuesta y Modelo de seguridad de red superpuesta en modo Docker Swarm.
Conceder a un servicio acceso a secretos
Para crear un servicio con acceso a secretos gestionados por Docker, utiliza la opción --secret. Para más información, consulta Gestionar cadenas sensibles (secretos) para servicios de Docker.
Personalizar el modo de aislamiento de un servicio
ImportantEsta configuración se aplica únicamente a hosts de Windows y se ignora en hosts de Linux.
Docker te permite especificar el modo de aislamiento de un servicio de swarm. El modo de aislamiento puede ser uno de los siguientes:
default: Utiliza el modo de aislamiento predeterminado configurado para el host de Docker, según lo establecido por la opción-exec-opto la matrizexec-optsendaemon.json. Si el demonio no especifica una tecnología de aislamiento,processes el predeterminado para Windows Server, yhyperves la opción predeterminada (y única) para Windows 10.process: Ejecuta las tareas del servicio como un proceso independiente en el host.NoteEl modo de aislamiento
processsolo es compatible con Windows Server. Windows 10 solo admite el modo de aislamientohyperv.hyperv: Ejecuta las tareas del servicio como tareas aisladas dehyperv. Esto aumenta la sobrecarga pero proporciona mayor aislamiento.
Puedes especificar el modo de aislamiento al crear o actualizar un nuevo servicio utilizando la opción --isolation.
Controlar la ubicación del servicio
Los servicios de Swarm proporcionan algunas formas diferentes de controlar la escala y la ubicación de los servicios en distintos nodos.
Puedes especificar si el servicio necesita ejecutar un número específico de réplicas o si debe ejecutarse globalmente en cada nodo trabajador. Consulta Servicios replicados o globales.
Puedes configurar los requisitos de CPU o memoria del servicio, y el servicio solo se ejecutará en nodos que puedan cumplir con esos requisitos.
Las restricciones de ubicación te permiten configurar el servicio para que se ejecute solo en nodos con metadatos específicos (arbitrarios) establecidos, y hacen que el despliegue falle si no existen los nodos adecuados. Por ejemplo, puedes especificar que tu servicio solo se ejecute en nodos donde una etiqueta arbitraria
pci_compliantesté establecida entrue.Las preferencias de ubicación te permiten aplicar una etiqueta arbitraria con un rango de valores a cada nodo y distribuir las tareas de tu servicio entre esos nodos utilizando un algoritmo. Actualmente, el único algoritmo admitido es
spread, que intenta distribuirlas de manera uniforme. Por ejemplo, si etiquetas cada nodo con una etiquetarackque tenga un valor del 1 al 10, y luego especificas una preferencia de ubicación con la claverack, las tareas del servicio se colocarán de la forma más uniforme posible en todos los nodos con la etiquetarack, después de tener en cuenta otras restricciones de ubicación, preferencias de ubicación y otras limitaciones específicas del nodo.A diferencia de las restricciones, las preferencias de ubicación se aplican según el principio del mejor esfuerzo (best-effort), y el despliegue de un servicio no falla si ningún nodo puede satisfacer la preferencia. Si especificas una preferencia de ubicación para un servicio, los nodos que coincidan con esa preferencia se clasificarán con mayor prioridad cuando los administradores del swarm decidan qué nodos deben ejecutar las tareas del servicio. Otros factores, como la alta disponibilidad del servicio, también influyen en los nodos programados para ejecutar las tareas del servicio. Por ejemplo, si tienes N nodos con la etiqueta de rack (y algunos otros), y tu servicio está configurado para ejecutar N+1 réplicas, la réplica +1 se programará en un nodo que aún no tenga el servicio, si hay alguno disponible, independientemente de si ese nodo tiene la etiqueta
racko no.
Servicios replicados o globales
El modo Swarm tiene dos tipos de servicios: replicados y globales. Para los servicios replicados, especificas el número de tareas de réplica que el administrador del swarm debe programar en los nodos disponibles. Para los servicios globales, el planificador coloca una tarea en cada nodo disponible que cumpla con las restricciones de ubicación del servicio y los requisitos de recursos.
Controlas el tipo de servicio utilizando la opción --mode. Si no especificas un modo, el servicio se establece por defecto en replicated. Para servicios replicados, especificas el número de tareas de réplica que deseas iniciar utilizando la opción --replicas. Por ejemplo, para iniciar un servicio nginx replicado con 3 tareas de réplica:
$ docker service create \
--name my_web \
--replicas 3 \
nginx
Para iniciar un servicio global en cada nodo disponible, pasa la opción --mode global a docker service create. Cada vez que un nuevo nodo esté disponible, el planificador colocará una tarea para el servicio global en el nuevo nodo. Por ejemplo, para iniciar un servicio que ejecute alpine en cada nodo del swarm:
$ docker service create \
--name myservice \
--mode global \
alpine top
Las restricciones de servicio te permiten establecer criterios que debe cumplir un nodo antes de que el planificador despliegue un servicio en él. Puedes aplicar restricciones al servicio basándote en los atributos y metadatos del nodo o en los metadatos del motor. Para más información sobre restricciones, consulta la referencia de la CLI de
docker service create.
Reservar memoria o CPUs para un servicio
Para reservar una cantidad determinada de memoria o número de CPU para un servicio, utiliza las opciones --reserve-memory o --reserve-cpu. Si ningún nodo disponible puede satisfacer el requisito (por ejemplo, si solicitas 4 CPU y ningún nodo del swarm tiene 4 CPU), el servicio permanecerá en estado pendiente (pending) hasta que esté disponible un nodo adecuado para ejecutar sus tareas.
Excepciones de falta de memoria (OOM)
Si tu servicio intenta utilizar más memoria de la que el nodo del swarm tiene disponible, puedes experimentar una excepción de falta de memoria (OOME) y el contenedor, o el demonio de Docker, podría ser finalizado por el finalizador de procesos OOM (OOM killer) del kernel. Para evitar que esto suceda, asegúrate de que tu aplicación se ejecute en hosts con memoria adecuada y consulta Comprender los riesgos de quedarse sin memoria.
Los servicios de Swarm te permiten utilizar restricciones de recursos, preferencias de ubicación y etiquetas para asegurar que tu servicio se despliegue en los nodos adecuados del swarm.
Restricciones de ubicación
Utiliza restricciones de ubicación para controlar los nodos a los que se puede asignar un servicio. En el siguiente ejemplo, el servicio solo se ejecuta en nodos con la etiqueta region establecida en east. Si no hay nodos etiquetados adecuadamente disponibles, las tareas esperarán en Pending hasta que lo estén. La opción --constraint utiliza un operador de igualdad (== o !=). Para servicios replicados, es posible que todos los servicios se ejecuten en el mismo nodo, o que cada nodo solo ejecute una réplica, o que algunos nodos no ejecuten ninguna réplica. Para servicios globales, el servicio se ejecuta en cada nodo que cumpla con la restricción de ubicación y cualquier requisito de recursos.
$ docker service create \
--name my-nginx \
--replicas 5 \
--constraint node.labels.region==east \
nginx
También puedes usar la clave constraint a nivel de servicio en un archivo compose.yaml.
Si especificas múltiples restricciones de ubicación, el servicio solo se desplegará en los nodos donde se cumplan todas ellas. El siguiente ejemplo limita el servicio para que se ejecute en todos los nodos donde region esté establecido en east y type no esté establecido en devel:
$ docker service create \
--name my-nginx \
--mode global \
--constraint node.labels.region==east \
--constraint node.labels.type!=devel \
nginx
También puedes utilizar restricciones de ubicación junto con preferencias de ubicación y restricciones de CPU/memoria. Ten cuidado de no utilizar configuraciones que no sean posibles de cumplir.
Para obtener más información sobre las restricciones, consulta la referencia de la CLI de
docker service create.
Preferencias de ubicación
Mientras que las restricciones de ubicación limitan los nodos en los que se puede ejecutar un servicio, las preferencias de ubicación intentan colocar las tareas en los nodos adecuados de forma algorítmica (actualmente, solo distribución uniforme). Por ejemplo, si asignas a cada nodo una etiqueta rack, puedes establecer una preferencia de ubicación para distribuir el servicio uniformemente entre los nodos con la etiqueta rack, según su valor. De esta forma, si pierdes un rack, el servicio seguirá ejecutándose en nodos de otros racks.
Las preferencias de ubicación no se aplican estrictamente. Si ningún nodo tiene la etiqueta que especificas en tu preferencia, el servicio se desplegará como si la preferencia no estuviera establecida.
NoteLas preferencias de ubicación se ignoran para los servicios globales.
El siguiente ejemplo establece una preferencia para distribuir el despliegue entre nodos en función del valor de la etiqueta datacenter. Si algunos nodos tienen datacenter=us-east y otros tienen datacenter=us-west, el servicio se despliega de la forma más uniforme posible entre los dos conjuntos de nodos.
$ docker service create \
--replicas 9 \
--name redis_2 \
--placement-pref 'spread=node.labels.datacenter' \
redis:7.4.0
NoteLos nodos que no tienen la etiqueta utilizada para la distribución (spread) siguen recibiendo asignaciones de tareas. Como grupo, estos nodos reciben tareas en la misma proporción que cualquiera de los otros grupos identificados por un valor de etiqueta específico. En cierto sentido, la ausencia de una etiqueta equivale a tener la etiqueta con un valor nulo. Si el servicio solo debe ejecutarse en nodos que tengan la etiqueta utilizada para la preferencia de distribución, esta preferencia debe combinarse con una restricción.
Puedes especificar múltiples preferencias de ubicación y estas se procesan en el orden en que se encuentran. El siguiente ejemplo configura un servicio con múltiples preferencias de ubicación. Las tareas se distribuyen primero en los diferentes centros de datos y luego en los racks (como lo indican las etiquetas respectivas):
$ docker service create \
--replicas 9 \
--name redis_2 \
--placement-pref 'spread=node.labels.datacenter' \
--placement-pref 'spread=node.labels.rack' \
redis:7.4.0
También puedes utilizar preferencias de ubicación junto con restricciones de ubicación o restricciones de CPU/memoria. Ten cuidado de no utilizar configuraciones que no sean posibles de cumplir.
Este diagrama ilustra cómo funcionan las preferencias de ubicación:
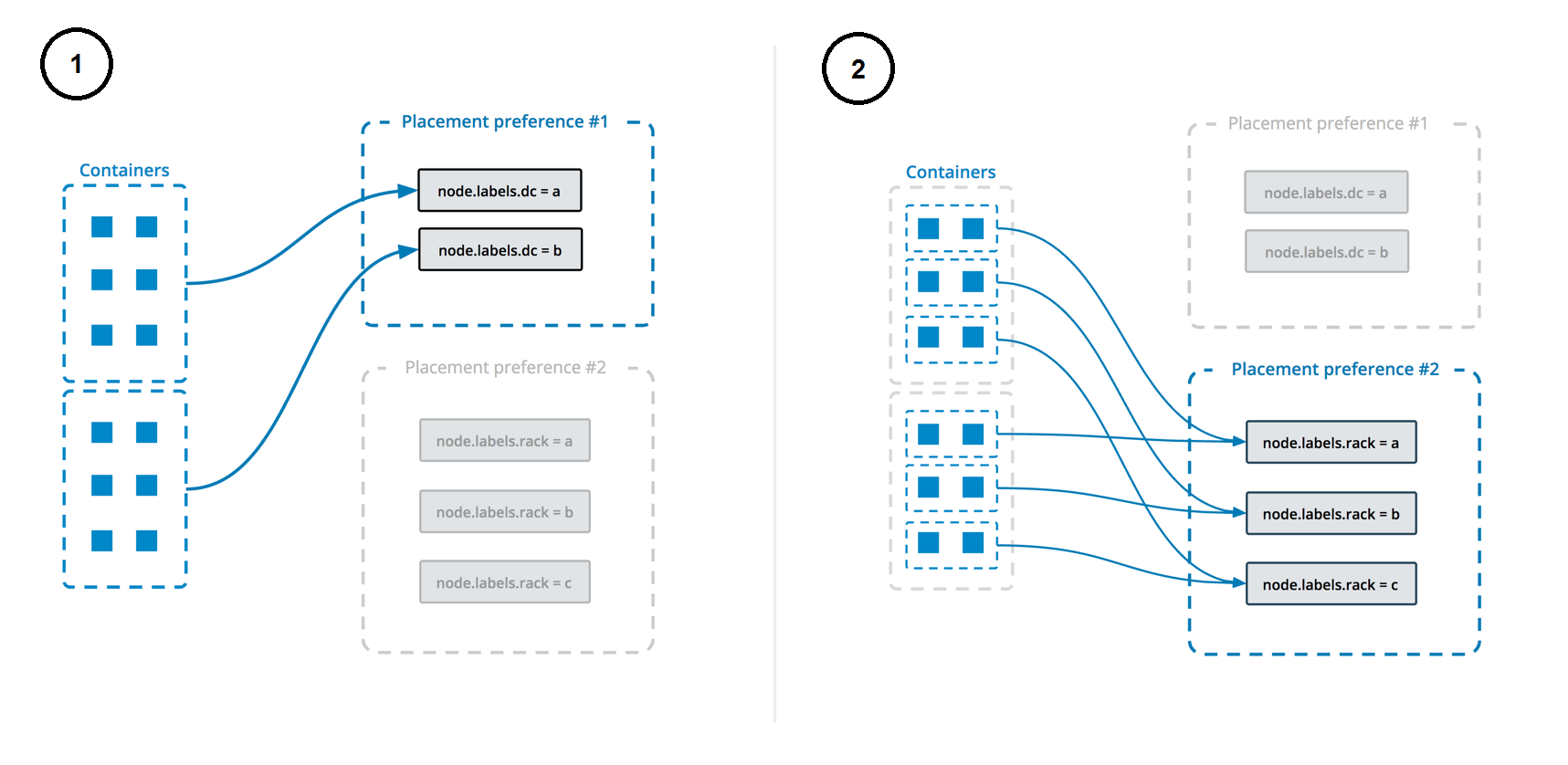
Al actualizar un servicio con docker service update, --placement-pref-add añade una nueva preferencia de ubicación después de todas las preferencias de ubicación existentes. --placement-pref-rm elimina una preferencia de ubicación existente que coincida con el argumento.
Configurar el comportamiento de actualización de un servicio
Al crear un servicio, puedes especificar un comportamiento de actualización continua (rolling update) sobre cómo el swarm debe aplicar los cambios al servicio cuando ejecutas docker service update. También puedes especificar estas opciones como parte de la actualización, como argumentos de docker service update.
La opción --update-delay configura el retraso de tiempo entre las actualizaciones de una tarea de servicio o conjuntos de tareas. Puedes describir el tiempo T como una combinación del número de segundos s, minutos m u horas h. De este modo, 10m30s indica un retraso de 10 minutos y 30 segundos.
Por defecto, el planificador actualiza 1 tarea a la vez. Puedes pasar la opción --update-parallelism para configurar el número máximo de tareas de servicio que el planificador actualiza de forma simultánea.
Cuando la actualización de una tarea individual devuelve el estado RUNNING, el planificador continúa la actualización procediendo con otra tarea hasta que todas las tareas se actualicen. Si en cualquier momento durante una actualización una tarea devuelve FAILED, el planificador pausa la actualización. Puedes controlar este comportamiento utilizando la opción --update-failure-action en docker service create o docker service update.
En el ejemplo de servicio a continuación, el planificador aplica actualizaciones a un máximo de 2 réplicas a la vez. Cuando una tarea actualizada devuelve RUNNING o FAILED, el planificador espera 10 segundos antes de detener la siguiente tarea para actualizar:
$ docker service create \
--replicas 10 \
--name my_web \
--update-delay 10s \
--update-parallelism 2 \
--update-failure-action continue \
alpine
La opción --update-max-failure-ratio controla qué fracción de tareas puede fallar durante una actualización antes de que la actualización en su conjunto se considere fallida. Por ejemplo, con --update-max-failure-ratio 0.1 --update-failure-action pause, después de que falle el 10% de las tareas que se están actualizando, la actualización se pausará.
Se considera que la actualización de una tarea individual ha fallado si la tarea no se inicia o si deja de ejecutarse dentro del período de supervisión especificado con la opción --update-monitor. El valor predeterminado para --update-monitor es de 30 segundos, lo que significa que una tarea que falle en los primeros 30 segundos después de iniciarse cuenta para el umbral de fallo de actualización del servicio, y cualquier fallo posterior no se contabiliza.
Revertir a la versión anterior de un servicio
En caso de que la versión actualizada de un servicio no funcione como se esperaba, es posible revertir manualmente a la versión anterior del servicio utilizando la opción --rollback de docker service update. Esto devuelve el servicio a la configuración que tenía antes del comando docker service update más reciente.
Otras opciones se pueden combinar con --rollback; por ejemplo, --update-delay 0s, para ejecutar la reversión sin retraso entre tareas:
$ docker service update \
--rollback \
--update-delay 0s \
my_web
Puedes configurar un servicio para que se revierta automáticamente si el despliegue de una actualización de servicio falla. Consulta Revertir automáticamente si falla una actualización.
La reversión manual se maneja en el lado del servidor, lo que permite que las reversiones iniciadas manualmente respeten los nuevos parámetros de reversión. Ten en cuenta que --rollback no se puede utilizar en combinación con otras opciones de docker service update.
Revertir automáticamente si falla una actualización
Puedes configurar un servicio de tal manera que si una actualización del servicio hace que falle el redespliegue, el servicio pueda revertirse automáticamente a la configuración anterior. Esto ayuda a proteger la disponibilidad del servicio. Puedes establecer una o más de las siguientes opciones al crear o actualizar el servicio. Si no estableces un valor, se utiliza el predeterminado.
| Opción | Predeterminado | Descripción |
|---|---|---|
--rollback-delay | 0s | Cantidad de tiempo a esperar después de revertir una tarea antes de revertir la siguiente. Un valor de 0 significa revertir la segunda tarea inmediatamente después del despliegue de la primera tarea revertida. |
--rollback-failure-action | pause | Cuando una tarea falla al revertirse, si se debe pausar (pause) o continuar (continue) intentando revertir otras tareas. |
--rollback-max-failure-ratio | 0 | La tasa de fallos tolerada durante una reversión, especificada como un número de coma flotante entre 0 y 1. Por ejemplo, dadas 5 tareas, una tasa de fallos de .2 toleraría que una tarea falle al revertirse. Un valor de 0 significa que no se toleran fallos, mientras que un valor de 1 significa que se tolera cualquier cantidad de fallos. |
--rollback-monitor | 5s | Duración después de la reversión de cada tarea para supervisar si hay fallos. Si una tarea se detiene antes de que transcurra este período de tiempo, se considera que la reversión ha fallado. |
--rollback-parallelism | 1 | El número máximo de tareas a revertir en paralelo. Por defecto, se revierte una tarea a la vez. Un valor de 0 hace que todas las tareas se reviertan en paralelo. |
El siguiente ejemplo configura un servicio redis para revertirse automáticamente si falla el despliegue de un docker service update. Se pueden revertir dos tareas en paralelo. Las tareas se supervisan durante 20 segundos después de la reversión para asegurarse de que no finalicen, y se tolera una tasa de fallos máxima del 20%. Se utilizan los valores predeterminados para --rollback-delay y --rollback-failure-action.
$ docker service create --name=my_redis \
--replicas=5 \
--rollback-parallelism=2 \
--rollback-monitor=20s \
--rollback-max-failure-ratio=.2 \
redis:latest
Conceder a un servicio acceso a volúmenes o montajes de tipo bind
Para obtener el mejor rendimiento y portabilidad, debes evitar escribir datos importantes directamente en la capa de escritura de un contenedor. En su lugar, debes utilizar volúmenes de datos o montajes de tipo bind. Este principio también se aplica a los servicios.
Puedes crear dos tipos de montajes para los servicios en un swarm: montajes de tipo volume (volumen) o montajes de tipo bind. Independientemente del tipo de montaje que utilices, configúralo con la opción --mount al crear un servicio, o con las opciones --mount-add o --mount-rm al actualizar un servicio existente. El valor predeterminado es un volumen de datos si no especificas un tipo.
Volúmenes de datos
Los volúmenes de datos son almacenamiento que existe de forma independiente a un contenedor. El ciclo de vida de los volúmenes de datos en los servicios de swarm es similar al de los contenedores. Los volúmenes sobreviven a las tareas y servicios, por lo que su eliminación debe gestionarse por separado. Los volúmenes se pueden crear antes de desplegar un servicio, o si no existen en un host particular cuando se programa una tarea allí, se crean automáticamente según la especificación del volumen en el servicio.
Para utilizar volúmenes de datos existentes con un servicio, utiliza la opción --mount:
$ docker service create \
--mount src=<VOLUME-NAME>,dst=<CONTAINER-PATH> \
--name myservice \
<IMAGE>
Si no existe un volumen con el nombre <VOLUME-NAME> cuando se programa una tarea en un host específico, se creará uno. El controlador de volumen predeterminado es local. Para utilizar un controlador de volumen diferente con este patrón de creación bajo demanda, especifica el controlador y sus opciones con la opción --mount:
$ docker service create \
--mount type=volume,src=<VOLUME-NAME>,dst=<CONTAINER-PATH>,volume-driver=<DRIVER>,volume-opt=<KEY0>=<VALUE0>,volume-opt=<KEY1>=<VALUE1> \
--name myservice \
<IMAGE>
Para obtener más información sobre cómo crear volúmenes de datos y el uso de controladores de volumen, consulta Usar volúmenes.
Montajes de tipo bind (Bind mounts)
Los montajes de tipo bind son rutas del sistema de archivos del host donde el planificador despliega el contenedor para la tarea. Docker monta la ruta dentro del contenedor. La ruta del sistema de archivos debe existir antes de que el swarm inicialice el contenedor para la tarea.
Los siguientes ejemplos muestran la sintaxis de los montajes de tipo bind:
Para montar una vinculación de lectura y escritura (read-write bind):
$ docker service create \ --mount type=bind,src=<HOST-PATH>,dst=<CONTAINER-PATH> \ --name myservice \ <IMAGE>Para montar una vinculación de solo lectura (read-only bind):
$ docker service create \ --mount type=bind,src=<HOST-PATH>,dst=<CONTAINER-PATH>,readonly \ --name myservice \ <IMAGE>
ImportantLos montajes de tipo bind pueden ser útiles, pero también pueden causar problemas. En la mayoría de los casos, se recomienda diseñar tu aplicación de manera que no sea necesario montar rutas desde el host. Los principales riesgos incluyen los siguientes:
Si montas una ruta del host en los contenedores de tu servicio, la ruta debe existir en cada nodo del swarm. El planificador del modo swarm de Docker puede programar contenedores en cualquier máquina que cumpla con los requisitos de disponibilidad de recursos y satisfaga todas las restricciones y preferencias de ubicación que especifiques.
El planificador del modo swarm de Docker puede reprogramar los contenedores de tu servicio en ejecución en cualquier momento si no están saludables o si se vuelven inaccesibles.
Los montajes de tipo bind del host no son portables. Cuando los utilizas, no hay garantía de que tu aplicación funcione de la misma manera en desarrollo que en producción.
Crear servicios utilizando plantillas
Puedes utilizar plantillas para algunas opciones de service create, utilizando la sintaxis proporcionada por el paquete text/template de Go.
Se admiten las siguientes opciones:
--hostname--mount--env
Los marcadores de posición válidos para la plantilla de Go son:
| Marcador de posición | Descripción |
|---|---|
.Service.ID | ID del servicio |
.Service.Name | Nombre del servicio |
.Service.Labels | Etiquetas del servicio |
.Node.ID | ID del nodo |
.Node.Hostname | Nombre de host del nodo |
.Task.Name | Nombre de la tarea |
.Task.Slot | Slot de la tarea |
Ejemplo de plantilla
Este ejemplo establece la plantilla de los contenedores creados en función del nombre del servicio y el ID del nodo donde se ejecuta el contenedor:
$ docker service create --name hosttempl \
--hostname="{{.Node.ID}}-{{.Service.Name}}"\
busybox top
Para ver el resultado de utilizar la plantilla, utiliza los comandos docker service ps y docker inspect.
$ docker service ps va8ew30grofhjoychbr6iot8c
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
wo41w8hg8qan hosttempl.1 busybox:latest@sha256:29f5d56d12684887bdfa50dcd29fc31eea4aaf4ad3bec43daf19026a7ce69912 2e7a8a9c4da2 Running Running about a minute ago
$ docker inspect --format="{{.Config.Hostname}}" hosttempl.1.wo41w8hg8qanxwjwsg4kxpprj