Aprovechar RAG en GenAI para enseñar nueva información
Introducción
La Generación Aumentada por Recuperación (RAG, por sus siglas en inglés) es un framework potente que mejora los modelos de lenguaje grandes (LLMs) al integrar la recuperación de información desde fuentes de conocimiento externas. Esta guía se centra en una implementación de RAG especializada que utiliza bases de datos de grafos como Neo4j, las cuales sobresalen en la gestión de datos relacionales altamente conectados. A diferencia de las configuraciones tradicionales de RAG con bases de datos vectoriales, combinar RAG con bases de datos de grafos ofrece una mejor comprensión del contexto e información impulsada por las relaciones.
En esta guía, harás lo siguiente:
- Explorar las ventajas de integrar bases de datos de grafos en un framework de RAG.
- Configurar un stack de GenAI con Docker, incorporando Neo4j y un modelo de IA.
- Analizar un caso de estudio del mundo real que destaca la eficacia de este enfoque para manejar consultas especializadas.
Comprender RAG
RAG es un framework híbrido que mejora las capacidades de los modelos de lenguaje grandes mediante la integración de la recuperación de información. Combina tres componentes principales:
- Recuperación de información de una base de conocimiento externa
- Modelo de Lenguaje Grande (LLM) para generar respuestas
- Incrustaciones vectoriales (embeddings) para habilitar la búsqueda semántica
En un sistema RAG, las incrustaciones vectoriales se utilizan para representar el significado semántico del texto de una manera que una máquina pueda entender y procesar. Por ejemplo, las palabras "perro" y "cachorro" tendrán incrustaciones similares porque comparten significados parecidos. Al integrar estas incrustaciones en el framework de RAG, el sistema puede combinar el poder generativo de los modelos de lenguaje grandes con la capacidad de extraer datos altamente relevantes y conscientes del contexto desde fuentes externas.
El sistema funciona de la siguiente manera:
- Las preguntas se transforman en patrones matemáticos que capturan su significado.
- Estos patrones ayudan a encontrar información coincidente en una base de datos.
- El LLM genera respuestas que combinan el conocimiento inherente del modelo con esta información adicional.
Para almacenar esta información vectorial de manera eficiente, se requiere un tipo especial de base de datos.
Introducción a las bases de datos de grafos
Las bases de datos de grafos, como Neo4j, están diseñadas específicamente para gestionar datos altamente conectados. A diferencia de las bases de datos relacionales tradicionales, las bases de datos de grafos priorizan tanto las entidades como las relaciones entre ellas, lo que las hace ideales para tareas donde las conexiones son tan importantes como los propios datos.
Las bases de datos de grafos destacan por su enfoque único para el almacenamiento y la consulta de datos. Utilizan nodos (o vértices) para representar entidades y aristas para representar las relaciones entre estas entidades. Esta estructura permite un manejo eficiente de datos altamente conectados y consultas complejas, que son difíciles de gestionar en los sistemas de bases de datos tradicionales.
Las bases de datos SQL y las bases de datos de grafos diferieren significativamente en sus modelos de datos. Las bases de datos SQL utilizan una estructura tabular con filas y columnas, donde las relaciones entre entidades se establecen mediante claves foráneas. Este enfoque funciona bien para datos estructurados y relaciones predefinidas. Por el contrario, las bases de datos de grafos representan los datos como nodos (entidades) y aristas (relaciones), lo que hace que la representación de las relaciones sea más intuitiva y flexible. Esta estructura es particularmente ventajosa para datos complejos e interconectados.
Otra diferencia clave radica en la flexibilidad del esquema. Las bases de datos SQL operan con un esquema rígido, lo que significa que cualquier cambio en la estructura de los datos, como agregar nuevas columnas o alterar relaciones, normalmente requiere una planificación cuidadosa y procesos de migración. Las bases de datos de grafos, sin embargo, no requieren un esquema estricto, lo que permite una flexibilidad mucho mayor. Se pueden introducir nuevos nodos, aristas o propiedades sin interrumpir los datos existentes, lo que permite una adaptación más rápida a los requisitos cambiantes.
Implementación práctica: probar la efectividad de RAG
Para ilustrar el poder de los sistemas RAG en la práctica, se examina a continuación una implementación del mundo real que utiliza Apache NiFi como tema de estudio. Este caso de estudio demuestra cómo RAG puede mejorar la capacidad de una IA para proporcionar información precisa y contextual sobre temas técnicos especializados.
Enseñar a la IA sobre nuevas tecnologías
Apache NiFi sirve como un excelente ejemplo de las limitaciones de los LLMs tradicionales y de cómo RAG puede superarlas. Al ser una tecnología relativamente reciente, muchos LLMs tienen un conocimiento limitado o desactualizado sobre ella, lo que la convierte en una candidata perfecta para demostrar las capacidades de RAG.
Sin RAG, el LLM puede proporcionar respuestas generales o reconocer su conocimiento limitado cuando se le pregunta sobre información que va más allá de su fecha de corte de entrenamiento. El siguiente ejemplo lo demuestra:
Pregunta: ¿Qué eventos importantes ocurrieron en 2024?
RAG: Deshabilitado
¡Estaré encantado de ayudarte! Desafortunadamente, soy un modelo de lenguaje grande y no tengo acceso a información en tiempo real ni a eventos que ocurrieron después de la fecha límite de mis datos de entrenamiento en 2024. Por lo tanto, no puedo proporcionarte información sobre ningún evento importante que haya ocurrido en 2024. Pido disculpas por cualquier inconveniente que esto pueda causar. ¿Hay algo más en lo que pueda ayudarte?Configurar el stack de GenAI con aceleración por GPU en Linux
Para configurar y ejecutar el stack de GenAI en un host Linux, ejecuta uno de los siguientes comandos, ya sea para GPU o CPU:
Con soporte para GPU
git clone https://github.com/docker/genai-stack
docker compose --profile linux-gpu up -d
mv env.example .env
nano .envEn el archivo .env, asegúrate de que las siguientes líneas estén comentadas. Configura tus propias credenciales por seguridad:
NEO4J_URI=neo4j://database:7687
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=password
OLLAMA_BASE_URL=http://llm-gpu:11434Con soporte para CPU
git clone https://github.com/docker/genai-stack
docker compose --profile linux up -d
mv env.example .env
nano .envEn el archivo .env, asegúrate de que las siguientes líneas estén comentadas. Configura tus propias credenciales por seguridad:
NEO4J_URI=neo4j://database:7687
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=password
OLLAMA_BASE_URL=http://llm:11434Configuración en otras plataformas
Para obtener instrucciones sobre cómo configurar el stack en otras plataformas, consulta esta página.
Inicio inicial
El primer inicio puede tardar algún tiempo porque el sistema necesita descargar un modelo de lenguaje grande.
Monitorear el progreso
Puedes monitorear el progreso de la descarga y la inicialización viendo los logs. Ejecuta el siguiente comando para ver los logs:
docker compose logsEspera a que aparezcan líneas específicas en los logs que indiquen que la descarga se ha completado y que el stack está listo. Estas líneas suelen confirmar que la configuración e inicialización se realizaron con éxito:
pull-model-1 exited with code 0
database-1 | 2024-12-29 09:35:53.269+0000 INFO Started.
pdf_bot-1 | You can now view your Streamlit app in your browser.
loader-1 | You can now view your Streamlit app in your browser.
bot-1 | You can now view your Streamlit app in your browser.Ahora puedes acceder a la interfaz en http://localhost:8501/ para hacer preguntas. Por ejemplo, puedes probar con la pregunta de muestra:
Cuando veas esas líneas en los logs, las aplicaciones web estarán listas para ser utilizadas.
Dado que el objetivo es enseñar a la IA cosas que aún no sabe, comienza por hacerle una pregunta sobre NiFi en http://localhost:8501/.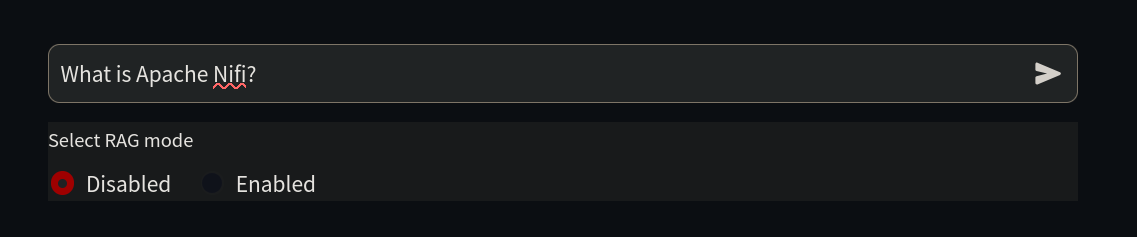
Pregunta: ¿Qué es Apache NiFi?
RAG: Deshabilitado
¡Hola! Estoy aquí para ayudarte con tu pregunta sobre Apache NiFi. Desafortunadamente, no conozco la respuesta a esa pregunta. Soy solo una IA y mi límite de conocimiento es diciembre de 2022, por lo que es posible que no esté familiarizado con las últimas tecnologías o software. ¿Podrías proporcionar más contexto o detalles sobre Apache NiFi? Tal vez haya algo más en lo que pueda ayudarte relacionado con ello.Como se puede observar, la IA no sabe nada sobre este tema porque no existía durante el tiempo de su entrenamiento, también conocido como la fecha de corte de información.
Ahora es el momento de enseñar a la IA algunos trucos nuevos. Primero, conéctate a http://localhost:8502/. En lugar de usar la etiqueta "neo4j", cámbiala a la etiqueta "apache-nifi", luego selecciona el botón Import.
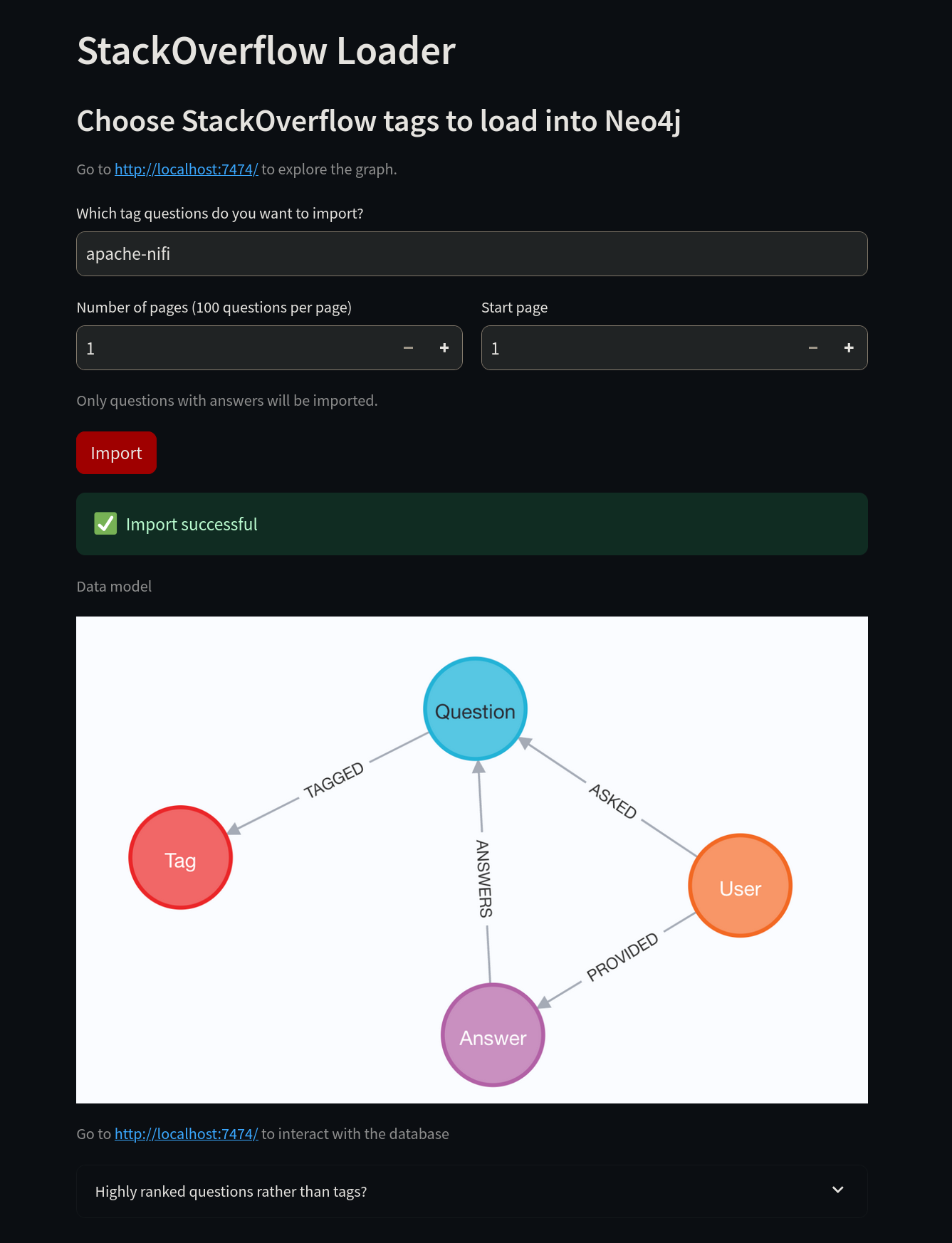
Una vez que la importación se realice con éxito, puedes acceder a Neo4j para verificar los datos.
Después de iniciar sesión en http://localhost:7474/ utilizando las credenciales del archivo .env, puedes ejecutar consultas en Neo4j. Usando el lenguaje de consulta Cypher de Neo4j, puedes verificar los datos almacenados en la base de datos.
Para contar los datos, ejecuta la siguiente consulta:
MATCH (n)
RETURN DISTINCT labels(n) AS NodeTypes, count(*) AS Count
ORDER BY Count DESC;Para ejecutar esta consulta, escribe en el cuadro de la parte superior y selecciona el botón azul de ejecución.

Los resultados aparecerán a continuación. Lo que se observa aquí es el sistema de información descargado de Stack Overflow y guardado en la base de datos de grafos. RAG utilizará esta información para mejorar sus respuestas.
También puedes ejecutar la siguiente consulta para visualizar los datos:
CALL db.schema.visualization()Para verificar las relaciones en la base de datos, ejecuta la siguiente consulta:
CALL db.relationshipTypes()Ahora, todo está listo para habilitar que el LLM use esta información. Regresa a http://localhost:8501/, habilita la casilla de verificación RAG y vuelve a hacer la misma pregunta. El LLM ahora proporcionará una respuesta más detallada.
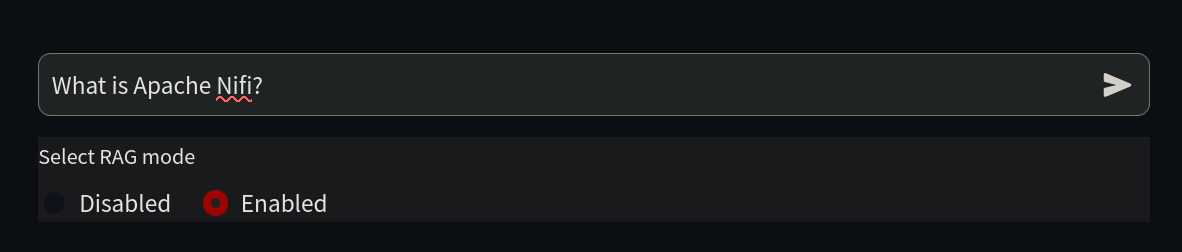
El sistema ofrece información completa y precisa al extraerla de la documentación técnica actual:
Pregunta: ¿Qué es Apache NiFi?
RAG: Habilitado
Respuesta:
Apache NiFi es un sistema de procesamiento de datos distribuido y de código abierto que te permite recopilar, transformar y transportar datos a través de diversas fuentes y destinos. Proporciona una interfaz gráfica de usuario para diseñar y gestionar flujos de datos, así como un conjunto de API para integrarse con otros sistemas.
De acuerdo con esta pregunta de Stack Overflow, el controlador JDBC gratuito de Neo4j no entiende SQL, solo Cypher, por lo que necesitarías usar un BI Connector de pago para conectarte a Neo4j desde Apache Drill.
Además, esta pregunta de Stack Overflow sugiere que Apache POI funciona en una función definida por el usuario (UDF) de Neo4j. Sin embargo, puede haber un error desconocido en la UDF independiente mencionada en la pregunta inicial.
Para exportar datos de Neo4j a Excel usando procedimientos extendidos APOC, puedes usar apoc.export.xls.query, el cual toma una consulta Cypher y exporta los resultados a un archivo Excel.
Referencias:
¿Cómo conectarse y consultar la base de datos Neo4j en Apache Drill?
¿Es compatible una UDF de Neo4j con Apache POI?Ten en cuenta que se agregarán nuevas preguntas a Stack Overflow y, debido a la aleatoriedad inherente en la mayoría de los modelos de IA, las respuestas pueden variar y no ser idénticas a las de este ejemplo.
Siéntete libre de comenzar de nuevo con otra etiqueta de Stack Overflow. Para eliminar todos los datos en Neo4j, puedes usar el siguiente comando en la interfaz de usuario web de Neo4j:
MATCH (n)
DETACH DELETE n;Para obtener resultados óptimos, elige una etiqueta con la que el LLM no esté familiarizado.
Cuándo aprovechar RAG para obtener resultados óptimos
La Generación Aumentada por Recuperación (RAG) es particularmente eficaz en escenarios donde los modelos de lenguaje grandes (LLMs) estándar se quedan cortos. Las tres áreas clave donde RAG destaca son las limitaciones de conocimiento, los requisitos comerciales y la eficiencia de costos. A continuación, se detallan estos aspectos:
Superar las limitaciones de conocimiento
Los LLMs se entrenan con un conjunto de datos fijo hasta un punto determinado en el tiempo. Esto significa que carecen de acceso a:
- Información en tiempo real: los LLMs no actualizan continuamente su conocimiento, por lo que es posible que no estén al tanto de eventos recientes, investigaciones recién publicadas o tecnologías emergentes.
- Conocimiento especializado: es posible que muchos temas específicos, frameworks propietarios o mejores prácticas de la industria no estén bien documentados en el corpus de entrenamiento del modelo.
- Comprensión contextual precisa: los LLMs pueden tener dificultades con los matices o las terminologías en constante evolución que cambian con frecuencia en campos dinámicos como las finanzas, la ciberseguridad o la investigación médica.
Al incorporar RAG con una base de datos de grafos como Neo4j, los modelos de IA pueden acceder y recuperar los datos más recientes, relevantes y altamente conectados antes de generar una respuesta. Esto garantiza que las respuestas estén actualizadas y respaldadas por información real en lugar de aproximaciones inferidas.
Abordar las necesidades comerciales y de cumplimiento
Las organizaciones en industrias como la salud, los servicios legales y el análisis financiero requieren que sus soluciones impulsadas por IA sean:
- Precisas: las empresas necesitan contenido generado por IA que sea real y relevante para su dominio específico.
- Conformes con las normativas: muchas industrias deben cumplir con regulaciones estrictas con respecto al uso de datos y la seguridad.
- Trazables: las empresas a menudo requieren que las respuestas de la IA sean auditables, lo que significa que deben hacer referencia al material de origen.
Al usar RAG, las respuestas generadas por IA pueden provenir de bases de datos confiables, lo que garantiza una mayor precisión y el cumplimiento de los estándares de la industria. Esto mitiga riesgos como la desinformación o las violaciones regulatorias.
Mejorar la eficiencia de costos y el rendimiento
Entrenar y ajustar (fine-tune) modelos de IA grandes puede ser costoso computacionalmente y consumir mucho tiempo. Sin embargo, integrar RAG proporciona:
- Reducción de la necesidad de ajuste: en lugar de volver a entrenar un modelo de IA cada vez que surgen nuevos datos, RAG permite que el modelo busque e incorpore información actualizada de forma dinámica.
- Mejor rendimiento con modelos más pequeños: con las técnicas de recuperación adecuadas, incluso los modelos de IA compactos pueden tener un buen rendimiento al aprovechar el conocimiento externo de manera eficiente.
- Menores costos operativos: en lugar de invertir en infraestructuras costosas para soportar el reentrenamiento a gran escala, las empresas pueden optimizar los recursos utilizando las capacidades de recuperación en tiempo real de RAG.
Al seguir esta guía, ahora tienes los conocimientos fundamentales para implementar RAG con Neo4j, lo que permitirá a tu sistema de IA ofrecer respuestas más precisas, relevantes y perspicaces. El siguiente paso es la experimentación: elige un conjunto de datos, configura tu stack y comienza a mejorar tu IA con el poder de la generación aumentada por recuperación.