Transcripción de video y chat con GenAI
Descripción general
Esta guía presenta un proyecto de transcripción y análisis de video que utiliza un conjunto de tecnologías relacionadas con el GenAI Stack.
El proyecto muestra las siguientes tecnologías:
- Docker y Docker Compose
- OpenAI
- Whisper
- Incrustaciones vectoriales (embeddings)
- Finalizaciones de chat (chat completions)
- Pinecone
- Generación Aumentada por Recuperación (RAG)
Agradecimiento
Esta guía es una contribución de la comunidad. Docker desea agradecer a David Cardozo por su aportación a esta guía.
Requisitos previos
Tienes una clave de API de OpenAI.
NoteOpenAI es un servicio alojado por terceros y pueden aplicarse cargos.
Tienes una clave de API de Pinecone.
Tienes instalada la versión más reciente de Docker Desktop. Docker agrega nuevas características regularmente y algunas partes de esta guía pueden funcionar solo con la versión más reciente de Docker Desktop.
Tienes un cliente de Git. Los ejemplos de esta sección utilizan un cliente de Git basado en la línea de comandos, pero puedes usar cualquier cliente.
Acerca de la aplicación
La aplicación es un chatbot que puede responder preguntas a partir de un video. Además, proporciona marcas de tiempo del video que te ayudan a encontrar las fuentes utilizadas para responder tu pregunta.
Obtener y ejecutar la aplicación
Clona el repositorio de la aplicación de muestra. En una terminal, ejecuta el siguiente comando:
$ git clone https://github.com/Davidnet/docker-genai.gitEl proyecto contiene los siguientes directorios y archivos:
├── docker-genai/ │ ├── docker-bot/ │ ├── yt-whisper/ │ ├── .env.example │ ├── .gitignore │ ├── LICENSE │ ├── README.md │ └── docker-compose.yamlEspecifica tus claves de API. En el directorio
docker-genai, crea un archivo de texto llamado.envy especifica tus claves de API en su interior. A continuación se muestra el contenido del archivo.env.exampleque puedes consultar como ejemplo:#---------------------------------------------------------------------------- # OpenAI #---------------------------------------------------------------------------- OPENAI_TOKEN=your-api-key # Reemplaza tu-clave-de-api con tu clave de API personal #---------------------------------------------------------------------------- # Pinecone #---------------------------------------------------------------------------- PINECONE_TOKEN=your-api-key # Reemplaza tu-clave-de-api con tu clave de API personalCompila y ejecuta la aplicación. En una terminal, cambia al directorio
docker-genaiy ejecuta el siguiente comando:$ docker compose up --buildDocker Compose compila y ejecuta la aplicación basándose en los servicios definidos en el archivo
docker-compose.yaml. Cuando la aplicación se esté ejecutando, verás los logs de 2 servicios en la terminal.En los logs, verás que los servicios están expuestos en los puertos
8503y8504. Los dos servicios son complementarios entre sí.El servicio
yt-whisperse ejecuta en el puerto8503. Este servicio alimenta la base de datos de Pinecone con los videos que quieras archivar en tu base de conocimientos. La siguiente sección detalla este servicio.
Uso del servicio yt-whisper
El servicio yt-whisper es un servicio de procesamiento de videos de YouTube que utiliza el modelo Whisper de OpenAI para generar transcripciones de videos y almacenarlas en una base de datos de Pinecone. Los siguientes pasos muestran cómo usar el servicio:
Abre un navegador y accede al servicio yt-whisper en http://localhost:8503.
Una vez que aparezca la aplicación, en el campo Youtube URL especifica la URL de un video de YouTube y selecciona Submit. El siguiente ejemplo utiliza https://www.youtube.com/watch?v=yaQZFhrW0fU.
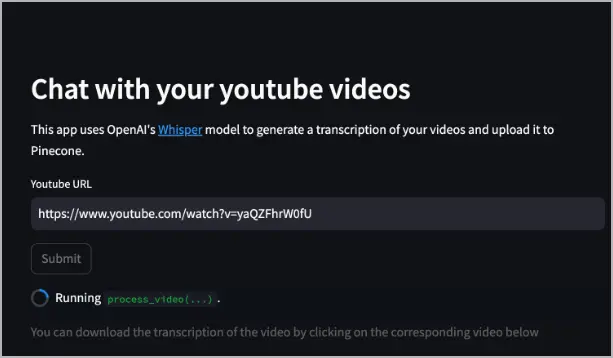
El servicio
yt-whisperdescarga el audio del video, utiliza Whisper para transcribirlo a un formato WebVTT (*.vtt) (que puedes descargar), luego utiliza el modelotext-embedding-3-smallpara crear las incrustaciones (embeddings) y, finalmente, sube esas incrustaciones a la base de datos de Pinecone.Después de procesar el video, aparecerá una lista de videos en la aplicación web que te informa qué videos se han indexado en Pinecone. También proporciona un botón para descargar la transcripción.
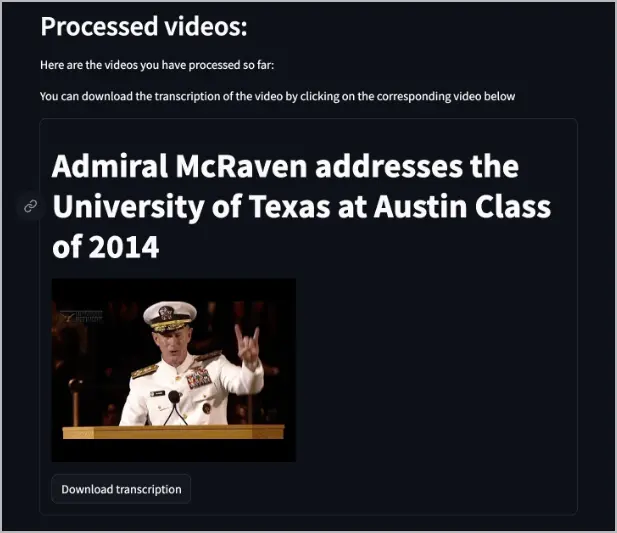
Ahora puedes acceder al servicio
dockerboten el puerto8504y hacer preguntas sobre los videos.
Uso del servicio dockerbot
El servicio dockerbot es un servicio de respuesta a preguntas que aprovecha tanto la base de datos de Pinecone como un modelo de IA para ofrecer respuestas. Los siguientes pasos muestran cómo usar el servicio:
NoteDebes procesar al menos un video a través del servicio yt-whisper antes de usar el servicio dockerbot.
Abre un navegador y accede al servicio en http://localhost:8504.
En el cuadro de texto What do you want to know about your videos?, hazle al Dockerbot una pregunta sobre un video que haya sido procesado por el servicio
yt-whisper. El siguiente ejemplo hace la pregunta, "What is a sugar cookie?". La respuesta a esa pregunta se encuentra en el video procesado en el ejemplo anterior, https://www.youtube.com/watch?v=yaQZFhrW0fU.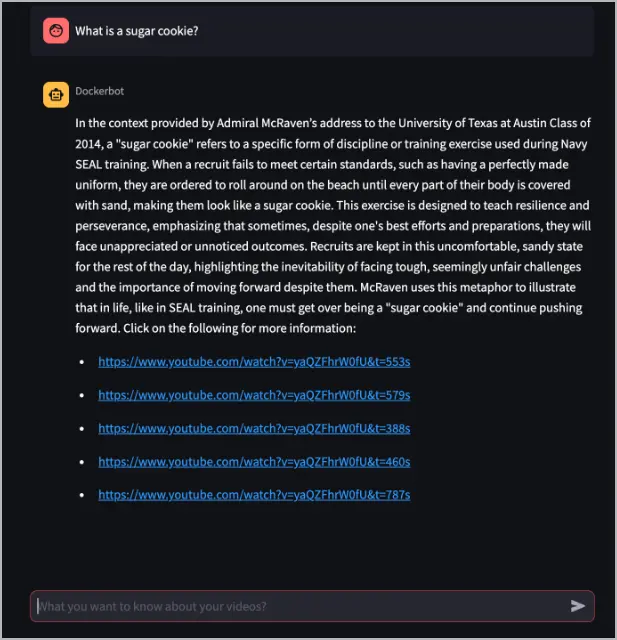
En este ejemplo, el Dockerbot responde a la pregunta y proporciona enlaces al video con marcas de tiempo, que pueden contener más información sobre la respuesta.
El servicio
dockerbottoma la pregunta, la convierte en una incrustación usando el modelotext-embedding-3-small, consulta la base de datos de Pinecone para encontrar incrustaciones similares y luego pasa ese contexto agpt-4-turbo-previewpara generar una respuesta.Selecciona el primer enlace para ver qué información proporciona. Con base en el ejemplo anterior, selecciona https://www.youtube.com/watch?v=yaQZFhrW0fU&t=553s.
En el enlace de ejemplo, puedes ver que esa sección del video responde perfectamente a la pregunta, "What is a sugar cookie?".
Explorar la arquitectura de la aplicación
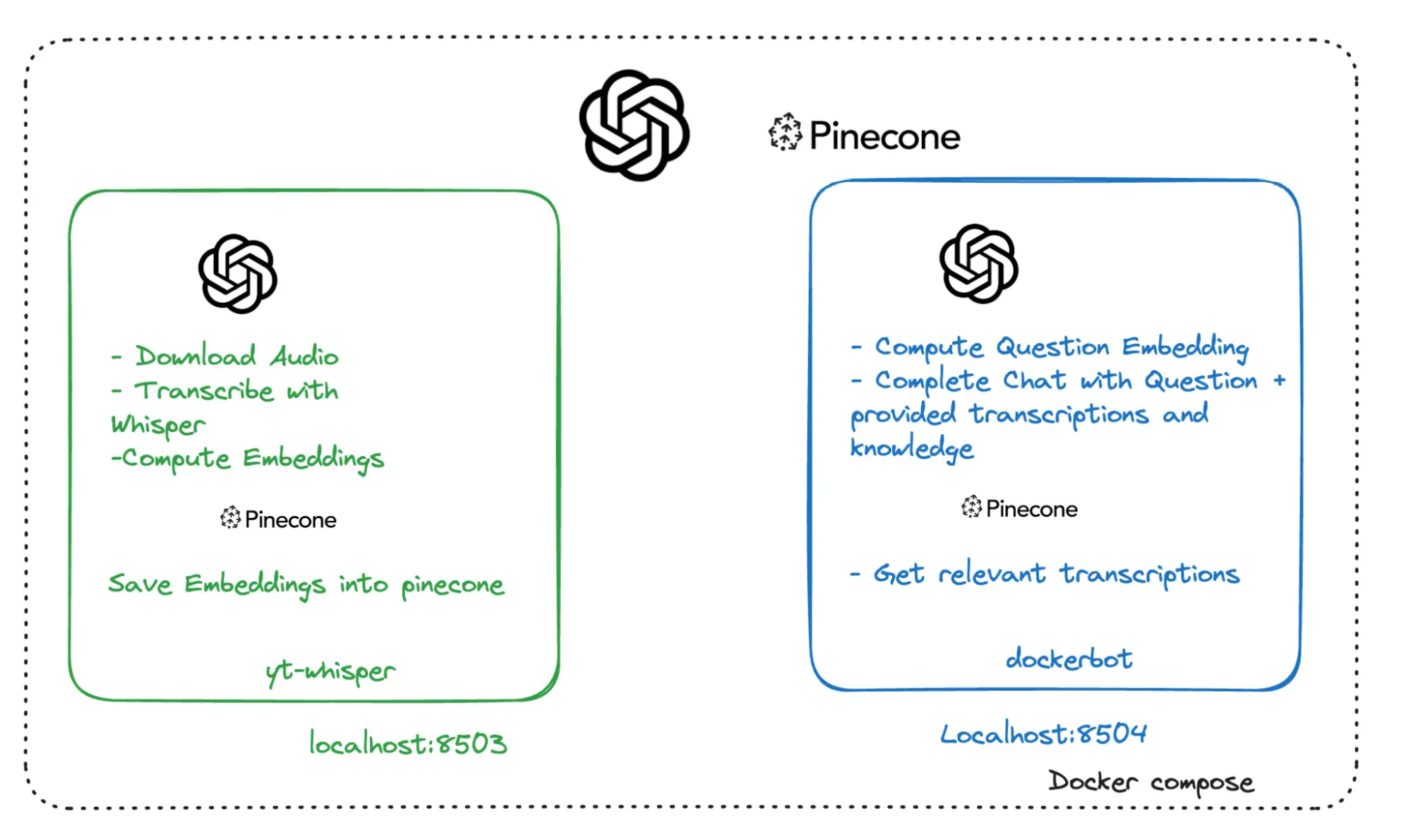
La siguiente imagen muestra la arquitectura de servicio de alto nivel de la aplicación, que incluye:
- yt-whisper: Un servicio local, ejecutado por Docker Compose, que interactúa con los servicios remotos de OpenAI y Pinecone.
- dockerbot: Un servicio local, ejecutado por Docker Compose, que interactúa con los servicios remotos de OpenAI y Pinecone.
- OpenAI: Un servicio remoto de terceros.
- Pinecone: Un servicio remoto de terceros.
Explorar las tecnologías utilizadas y su función
Docker y Docker Compose
La aplicación utiliza Docker para ejecutarse en contenedores, proporcionando un entorno consistente y aislado. Esto significa que la aplicación funcionará según lo previsto dentro de sus contenedores de Docker, independientemente de las diferencias del sistema subyente. Para obtener más información sobre Docker, consulta la Descripción general de introducción.
Docker Compose es una herramienta para definir y ejecutar aplicaciones multi-contenedor. Compose facilita la ejecución de esta aplicación con un solo comando: docker compose up. Para obtener más detalles, consulta la
Descripción general de Compose.
OpenAI API
La API de OpenAI proporciona un servicio de LLM conocido por sus tecnologías de IA y aprendizaje automático de vanguardia. En esta aplicación, la tecnología de OpenAI se utiliza para generar transcripciones a partir de audio (utilizando el modelo Whisper), crear incrustaciones para datos de texto y generar respuestas a las consultas de los usuarios (utilizando GPT y finalizaciones de chat). Para obtener más detalles, consulta openai.com.
Whisper
Whisper es un sistema de reconocimiento automático de voz desarrollado por OpenAI, diseñado para transcribir el lenguaje hablado en texto. En esta aplicación, Whisper se utiliza para transcribir el audio de los videos de YouTube a texto, lo que permite un procesamiento y análisis posterior del contenido del video. Para obtener más detalles, consulta Presentando Whisper.
Incrustaciones vectoriales (embeddings)
Las incrustaciones son representaciones numéricas de texto u otros tipos de datos que capturan su significado de manera que puedan ser procesados por algoritmos de aprendizaje automático. En esta aplicación, las incrustaciones se utilizan para convertir las transcripciones de video en un formato vectorial que se pueda consultar y analizar según su relevancia para la entrada del usuario, facilitando una búsqueda eficiente y la generación de respuestas. Para obtener más detalles, consulta la documentación de Embeddings de OpenAI.
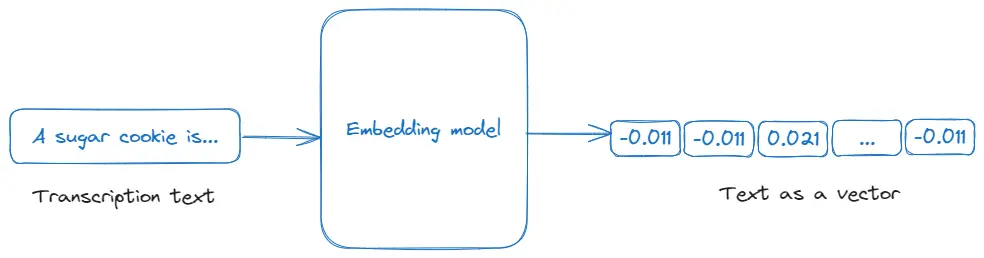
Finalizaciones de chat (chat completions)
La finalización de chat, como se utiliza en esta aplicación a través de la API de OpenAI, se refiere a la generación de respuestas conversacionales basadas en un contexto o prompt dado. En la aplicación, se utiliza para proporcionar respuestas inteligentes y conscientes del contexto a las consultas de los usuarios, procesando e integrando la información de las transcripciones de video y otras entradas, lo que mejora las capacidades interactivas del chatbot. Para obtener más detalles, consulta la documentación de la Chat Completions API de OpenAI.
Pinecone
Pinecone es un servicio de base de datos vectorial optimizado para la búsqueda de similitud, utilizado para construir y desplegar aplicaciones de búsqueda vectorial a gran escala. En esta aplicación, Pinecone se emplea para almacenar y recuperar las incrustaciones de las transcripciones de video, lo que permite una funcionalidad de búsqueda eficiente y relevante basada en las consultas de los usuarios. Para obtener más detalles, consulta pinecone.io.
Generación Aumentada por Recuperación (RAG)
La Generación Aumentada por Recuperación (RAG) es una técnica que combina la recuperación de información con un modelo de lenguaje para generar respuestas basadas en los documentos o datos recuperados. En RAG, el sistema recupera información relevante (en este caso, mediante incrustaciones de transcripciones de video) y luego utiliza un modelo de lenguaje para generar respuestas basadas en estos datos recuperados. Para obtener más detalles, consulta el cookbook de OpenAI para Preguntas y respuestas generativas aumentadas por recuperación con Pinecone.
Siguientes pasos
Explora cómo crear una aplicación de bot de PDF utilizando IA generativa, o consulta más muestras de GenAI en el repositorio de GenAI Stack.