Desarrollo de aplicaciones orientadas a eventos con Kafka y Docker
Con el auge de los microservicios, las arquitecturas orientadas a eventos se han vuelto cada vez más populares. Apache Kafka, una plataforma distribuida de transmisión de eventos, suele ser el núcleo de estas arquitecturas. Desafortunadamente, configurar y desplegar tu propia instancia de Kafka para desarrollo suele ser complicado. Por suerte, Docker y los contenedores lo hacen mucho más fácil.
En esta guía, aprenderás a:
- Usar Docker para iniciar un clúster de Kafka
- Conectar una aplicación no contenerizada al clúster
- Conectar una aplicación contenerizada al clúster
- Desplegar Kafka-UI para ayudar con la resolución de problemas y la depuración
Requisitos previos
Se requieren los siguientes requisitos previos para seguir esta guía práctica:
- Docker Desktop
- Node.js y yarn
- Conocimiento básico de Kafka y Docker
Iniciar Kafka
A partir de Kafka 3.3, el despliegue de Kafka se simplificó enormemente al no requerir Zookeeper gracias a KRaft (Kafka Raft). Con KRaft, configurar una instancia de Kafka para desarrollo local es mucho más sencillo. Con el lanzamiento de Kafka 3.8, ahora está disponible una nueva imagen de Docker kafka-native, que proporciona un inicio significativamente más rápido y un menor consumo de memoria.
TipEsta guía utilizará la imagen apache/kafka, ya que incluye muchas secuencias de comandos (scripts) útiles para gestionar y trabajar con Kafka. Sin embargo, es posible que prefieras utilizar la imagen apache/kafka-native, ya que se inicia más rápido y requiere menos recursos.
Iniciar Kafka
Inicia un clúster de Kafka básico siguiendo estos pasos. Este ejemplo iniciará un clúster exponiendo el puerto 9092 en el host para permitir que una aplicación que se ejecuta de forma nativa se conecte a él.
Inicia un contenedor de Kafka ejecutando el siguiente comando:
$ docker run -d --name=kafka -p 9092:9092 apache/kafkaUna vez descargada la imagen, tendrás una instancia de Kafka en funcionamiento en uno o dos segundos.
La imagen apache/kafka incluye varios scripts útiles en el directorio
/opt/kafka/bin. Ejecuta el siguiente comando para verificar que el clúster está en funcionamiento y obtener su ID de clúster:$ docker exec -ti kafka /opt/kafka/bin/kafka-cluster.sh cluster-id --bootstrap-server :9092Al hacerlo, se producirá una salida similar a la siguiente:
Cluster ID: 5L6g3nShT-eMCtK--X86swCrea un tema (topic) de ejemplo y publica (produce) algunos mensajes ejecutando el siguiente comando:
$ docker exec -ti kafka /opt/kafka/bin/kafka-console-producer.sh --bootstrap-server :9092 --topic demoDespués de ejecutarlo, puedes introducir un mensaje por línea. Por ejemplo, ingresa algunos mensajes, uno por línea. Algunos ejemplos podrían ser:
First messageY
Second messagePresiona
enterpara enviar el último mensaje y luego presionactrl+ccuando termines. Los mensajes se publicarán en Kafka.Confirma que los mensajes se publicaron en el clúster consumiendo los mensajes:
$ docker exec -ti kafka /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server :9092 --topic demo --from-beginningDeberías ver tus mensajes en la salida:
First message Second messageSi lo deseas, puedes abrir otra terminal, publicar más mensajes y ver cómo aparecen en el consumidor.
Cuando termines, presiona
ctrl+cpara detener la lectura de mensajes.
Ya tienes un clúster de Kafka ejecutándose localmente y has validado que puedes conectarte a él.
Conectarse a Kafka desde una aplicación no contenerizada
Ahora que has demostrado que puedes conectarte a la instancia de Kafka desde la línea de comandos, es hora de conectarte al clúster desde una aplicación. En este ejemplo, utilizarás un proyecto Node simple que usa la biblioteca KafkaJS.
Dado que el clúster se ejecuta localmente y está expuesto en el puerto 9092, la aplicación puede conectarse al clúster en localhost:9092 (ya que se ejecuta de forma nativa y no en un contenedor en este momento). Una vez conectada, esta aplicación de ejemplo registrará los mensajes que consuma del tema demo. Además, cuando se ejecute en modo de desarrollo, también creará el tema si no lo encuentra.
Si no tienes el clúster de Kafka ejecutándose del paso anterior, ejecuta el siguiente comando para iniciar una instancia de Kafka:
$ docker run -d --name=kafka -p 9092:9092 apache/kafkaClona el repositorio de GitHub localmente.
$ git clone https://github.com/dockersamples/kafka-development-node.gitNavega dentro del proyecto.
cd kafka-development-node/appInstala las dependencias usando yarn.
$ yarn installInicia la aplicación usando
yarn dev. Esto establecerá la variable de entornoNODE_ENVadevelopmenty usaránodemonpara vigilar los cambios de archivos.$ yarn devCon la aplicación en ejecución, registrará los mensajes recibidos en la consola. En una nueva terminal, publica algunos mensajes usando el siguiente comando:
$ docker exec -ti kafka /opt/kafka/bin/kafka-console-producer.sh --bootstrap-server :9092 --topic demoY luego envía un mensaje al clúster:
Test messageRecuerda presionar
ctrl+ccuando termines para dejar de producir mensajes.
Conectarse a Kafka tanto desde contenedores como desde aplicaciones nativas
Ahora que tienes una aplicación que se conecta a Kafka a través de su puerto expuesto, es hora de explorar qué cambios se necesitan para conectarse a Kafka desde otro contenedor. Para hacerlo, ahora ejecutarás la aplicación desde un contenedor en lugar de hacerlo de forma nativa.
Pero antes de hacerlo, es importante comprender cómo funcionan los oyentes (listeners) de Kafka y cómo ayudan a los clientes a conectarse.
Comprendiendo los oyentes (listeners) de Kafka
Cuando un cliente se conecta a un clúster de Kafka, en realidad se conecta a un "broker". Aunque los brokers tienen muchas funciones, una de ellas es admitir el equilibrio de carga de los clientes. Cuando un cliente se conecta, el broker devuelve un conjunto de URLs de conexión que el cliente debe usar para producir o consumir mensajes. ¿Cómo se configuran estas URLs de conexión?
Cada instancia de Kafka tiene un conjunto de listeners y advertised listeners. Los "listeners" son los puertos y direcciones a los que Kafka se enlaza, y los "advertised listeners" configuran cómo deben conectarse los clientes al clúster. La URL de conexión que recibe un cliente se basa en a qué listener se conecta.
Definiendo los oyentes (listeners)
Para que esto tenga sentido, veamos cómo debe configurarse Kafka para admitir dos escenarios de conexión:
- Conexiones del host (aquellas que pasan a través del puerto mapeado del host): estas deberán conectarse utilizando
localhost. - Conexiones de Docker (aquellas que provienen de las redes de Docker): estas no pueden conectarse utilizando
localhost, sino el alias de red (o dirección DNS) del servicio de Kafka.
Dado que existen dos métodos diferentes de conexión para los clientes, se requieren dos oyentes diferentes: HOST y DOCKER. El oyente HOST les indicará a los clientes que se conecten usando localhost:9092, mientras que el oyente DOCKER les informará que se conecten usando kafka:9093. Observa que esto significa que Kafka escucha tanto en el puerto 9092 como en el 9093. Sin embargo, solo el oyente del host necesita ser expuesto al host.
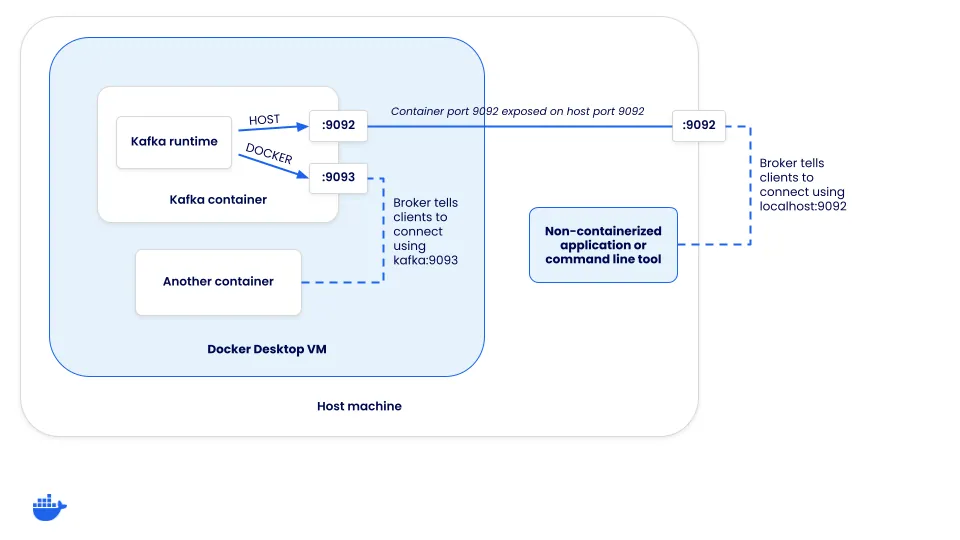
Para configurar esto, el archivo compose.yaml de Kafka necesita una configuración adicional. Una vez que comiences a sobrescribir algunos de los valores predeterminados, también deberás especificar algunas otras opciones para que funcione el modo KRaft.
services:
kafka:
image: apache/kafka-native
ports:
- "9092:9092"
environment:
# Configura oyentes tanto para la comunicación de docker como del host
KAFKA_LISTENERS: CONTROLLER://localhost:9091,HOST://0.0.0.0:9092,DOCKER://0.0.0.0:9093
KAFKA_ADVERTISED_LISTENERS: HOST://localhost:9092,DOCKER://kafka:9093
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,DOCKER:PLAINTEXT,HOST:PLAINTEXT
# Configuraciones requeridas para el modo KRaft
KAFKA_NODE_ID: 1
KAFKA_PROCESS_ROLES: broker,controller
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@localhost:9091
# Oyente a utilizar para la comunicación entre brokers
KAFKA_INTER_BROKER_LISTENER_NAME: DOCKER
# Requerido para un clúster de un solo nodo
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1Pruébalo siguiendo los pasos a continuación.
Si tienes la aplicación de Node ejecutándose del paso anterior, detenla presionando
ctrl+cen la terminal.Si tienes el clúster de Kafka ejecutándose del apartado anterior, detén ese contenedor con el siguiente comando:
$ docker rm -f kafkaInicia el entorno de Compose ejecutando el siguiente comando en la raíz del directorio del proyecto clonado:
$ docker compose upDespués de un momento, la aplicación estará en funcionamiento.
En el entorno de Compose hay otro servicio que se puede utilizar para publicar mensajes. Abre tu navegador en http://localhost:3000. A medida que escribas un mensaje y envíes el formulario, deberías ver el mensaje de registro de que la aplicación lo ha recibido.
Esto ayuda a demostrar cómo un enfoque contenerizado facilita la adición de servicios adicionales para ayudar a probar y solucionar problemas en tu aplicación.
Agregar visualización del clúster
Una vez que comiences a utilizar contenedores en tu entorno de desarrollo, te darás cuenta de la facilidad de agregar servicios adicionales enfocados únicamente en ayudar al desarrollo, como visualizadores y otros servicios auxiliares. Como ya tienes Kafka en ejecución, podría ser útil visualizar lo que ocurre en el clúster de Kafka. Para hacerlo, puedes ejecutar la aplicación web Kafbat UI.
Para agregarla a tu propio proyecto (ya se encuentra en la aplicación de demostración), solo necesitas agregar la siguiente configuración a tu archivo Compose:
services:
kafka-ui:
image: kafbat/kafka-ui:main
ports:
- 8080:8080
environment:
DYNAMIC_CONFIG_ENABLED: "true"
KAFKA_CLUSTERS_0_NAME: local
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka:9093
depends_on:
- kafkaLuego, una vez que se inicie el entorno de Compose, puedes abrir tu navegador en http://localhost:8080 y navegar para ver detalles adicionales sobre el clúster, verificar los consumidores, publicar mensajes de prueba y más.
Pruebas con Kafka
Si estás interesado en aprender cómo puedes integrar Kafka fácilmente en tus pruebas de integración, consulta la guía Pruebas de oyentes Kafka en Spring Boot usando Testcontainers. Esta guía te enseñará cómo usar Testcontainers para gestionar el ciclo de vida de los contenedores de Kafka en tus pruebas.
Conclusión
Al usar Docker, puedes simplificar el proceso de desarrollo y prueba de aplicaciones orientadas a eventos con Kafka. Los contenedores simplifican el proceso de configuración y despliegue de los distintos servicios que necesitas para el desarrollo. Y una vez definidos en Compose, todos los miembros del equipo pueden beneficiarse de esta facilidad de uso.
En caso de que te lo hayas perdido antes, todo el código de la aplicación de ejemplo se puede encontrar en dockersamples/kafka-development-node.